View the complete cookbook example on GitHub: honeyhiveai/cookbook/langgraph-cookbookThis guide demonstrates how to build a sophisticated code generation system using LangGraph and HoneyHive tracing. The system combines Retrieval Augmented Generation (RAG) with self-correction capabilities to generate reliable code solutions. HoneyHive’s tracing capabilities provide comprehensive visibility into the entire process, making debugging and optimization easier than ever.
Overview
The system consists of several key components:- Documentation loading and processing (traced with HoneyHive)
- LLM setup with structured output (monitored for performance)
- A LangGraph workflow for code generation and validation (with detailed tracing)
- HoneyHive tracing for monitoring and debugging (real-time insights)
Prerequisites
Before running this code, ensure you have the following:- Python 3.x
- Required API keys:
- HoneyHive API key (for comprehensive tracing)
- OpenAI API key
- Anthropic API key
- Required packages:
Code Implementation
Environment Setup and Imports
HoneyHive Tracing Setup
HoneyHive’s tracing setup provides comprehensive monitoring capabilities:- Real-time monitoring of all traced functions
- Detailed performance metrics
- Error tracking and debugging
- Session-based analytics
- Custom metadata support
Documentation Loading
The system uses RecursiveUrlLoader with HoneyHive tracing to monitor documentation loading:- Loading time metrics
- Document count tracking
- Error handling for failed loads
- Memory usage monitoring
- URL accessibility tracking
Data Model
The system uses Pydantic with HoneyHive tracing for structured output validation:- Model validation success rates
- Field completion rates
- Schema compliance
- Data quality metrics
LLM Setup
The system uses Claude with HoneyHive tracing for comprehensive LLM monitoring:- LLM response time tracking
- Token usage monitoring
- Error rate tracking
- Model performance analytics
- Cost tracking per request
Documentation Loading and Chain Setup
First, load the documentation and set up the code generation chain:LangGraph Implementation
The system uses LangGraph with HoneyHive tracing for workflow monitoring:- State Definition:
- Graph Nodes with HoneyHive tracing:
- Graph Construction with comprehensive tracing:
Main Execution Function
The main function to run the graph with a question:- Node execution time tracking
- Edge traversal monitoring
- State transition tracking
- Error propagation analysis
- Performance bottlenecks identification
Usage
To use the code generation system with HoneyHive monitoring:Key Features
- RAG Integration: HoneyHive traces document retrieval and processing
- Self-Correction: Monitors validation and improvement cycles
- Structured Output: Tracks schema compliance and data quality
- HoneyHive Tracing: Provides comprehensive monitoring and debugging
- Maximum Iterations: Tracks iteration counts and success rates
Best Practices
- Always set up proper environment variables before running
- Monitor the HoneyHive dashboard for:
- Performance metrics
- Error rates
- Cost analysis
- Usage patterns
- Adjust the max_depth parameter in RecursiveUrlLoader based on your needs
- Customize the reflection step based on your specific use case
- Implement proper error handling for production use
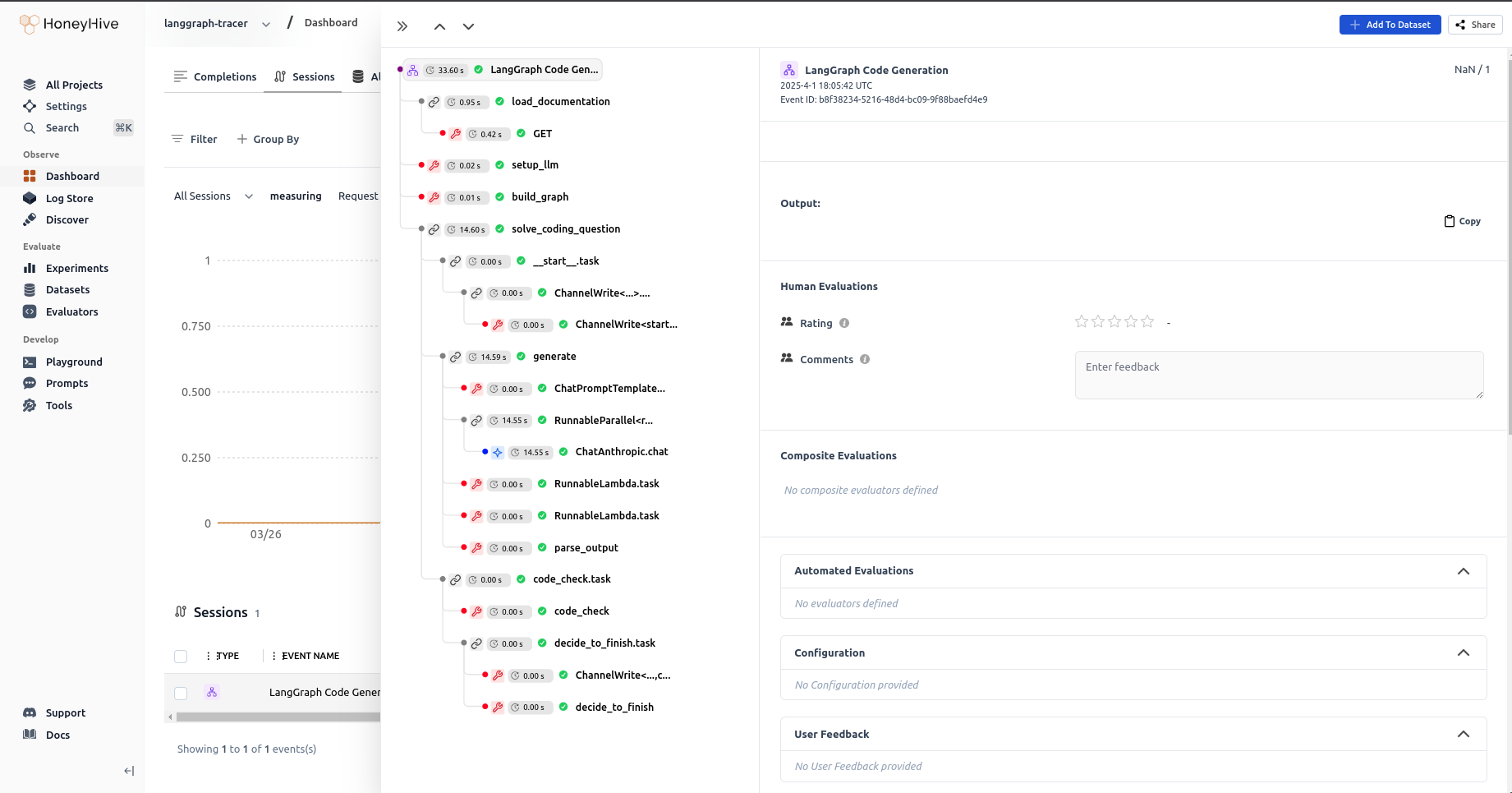
HoneyHive Dashboard Insights
The HoneyHive dashboard provides valuable insights:- Performance Metrics:
- Response times
- Throughput
- Resource usage
- Error Tracking:
- Error rates
- Stack traces
- Error patterns
- Cost Analysis:
- API usage costs
- Resource consumption
- Cost optimization opportunities
- Usage Patterns:
- Peak usage times
- Common operations
- User behavior
Conclusion
This implementation provides a robust foundation for code generation with self-correction capabilities. The combination of LangGraph and HoneyHive tracing ensures reliable and monitored code generation processes. HoneyHive’s comprehensive tracing capabilities make it easier to:- Debug issues
- Optimize performance
- Track costs
- Monitor quality
- Scale the system