Project
Everything in HoneyHive is organized by projects. A project is a logically-separated workspace to develop, evaluate, and monitor a specific AI agent or an end-to-end application leveraging one or multiple agents.Sessions & Events
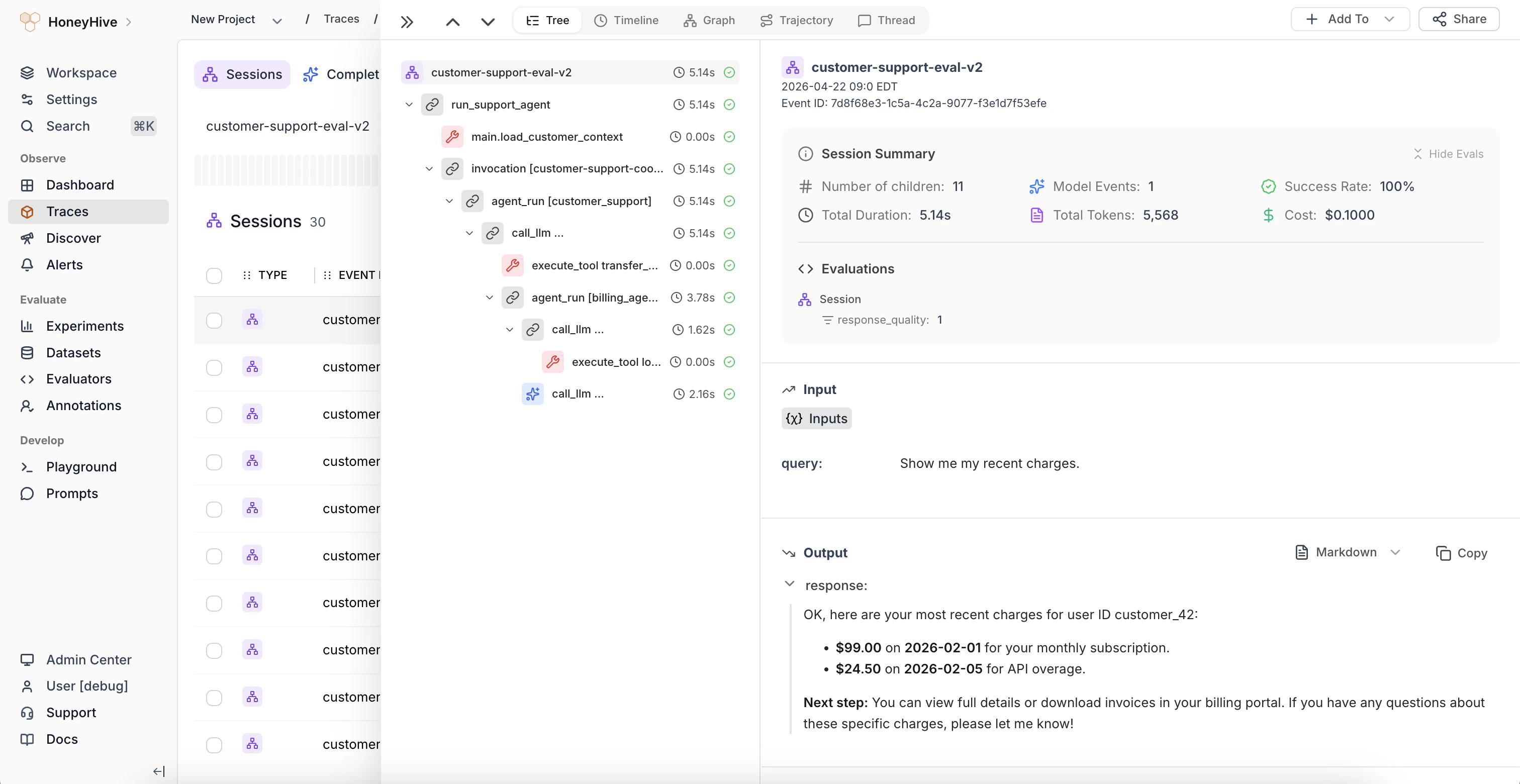
Event: Anevent tracks the execution of different parts of your application along with related metadata, user feedback and so on. This is synonymous with a single span in a trace.
Session: A session is a collection of events that are related to a single user interaction with your application, typically incorporating multiple turns. Sessions can be used to trace a single agent execution or the end-to-end user session, depending on your configuration.
Experiment Run
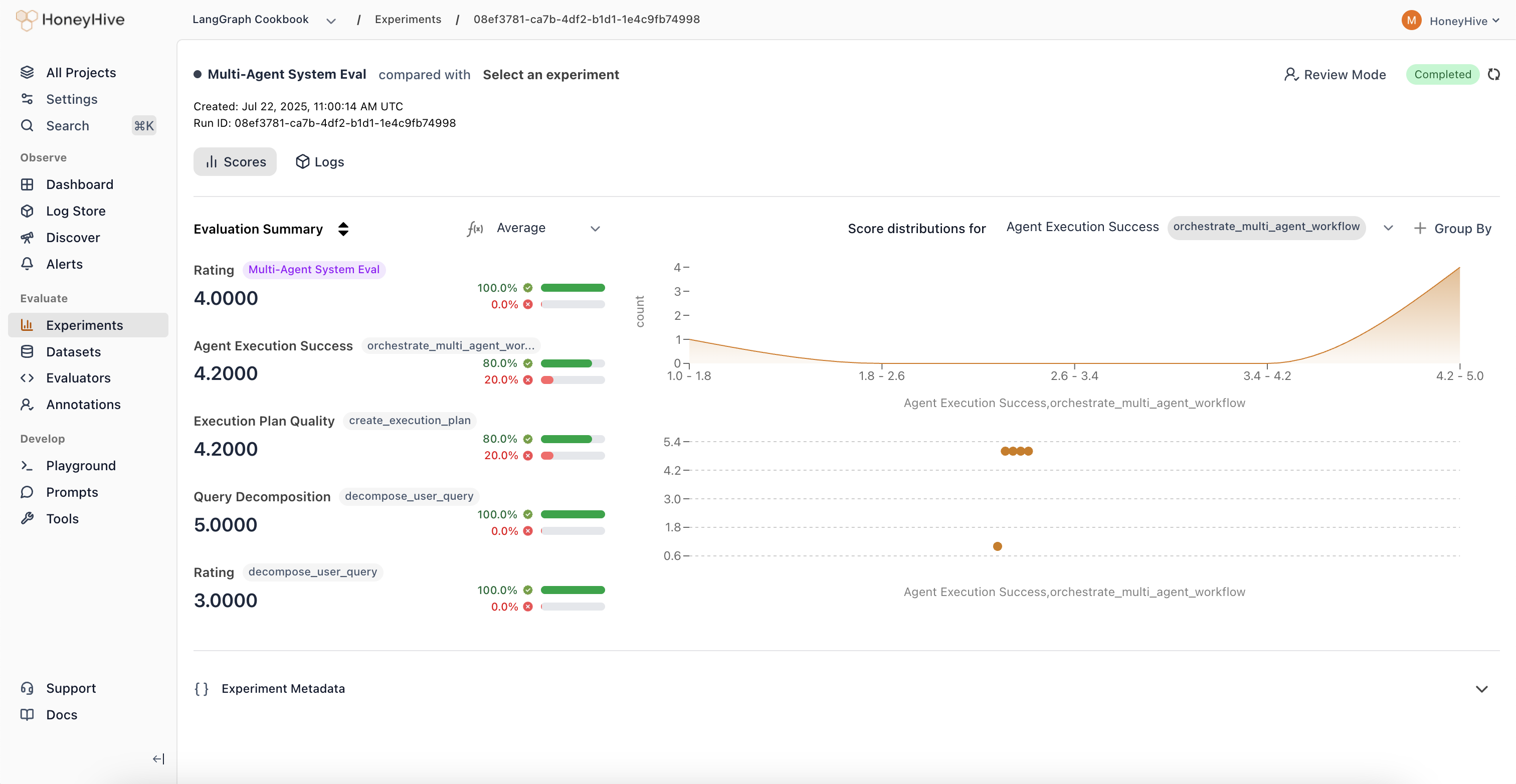
An experiment run is a collection of sessions that track the execution of your end-to-end application (or a single agent) based on a commonrun_id on metadata.
In our interface, we summarize the metrics present on the session & all its children. Presenting an interface as shown below:
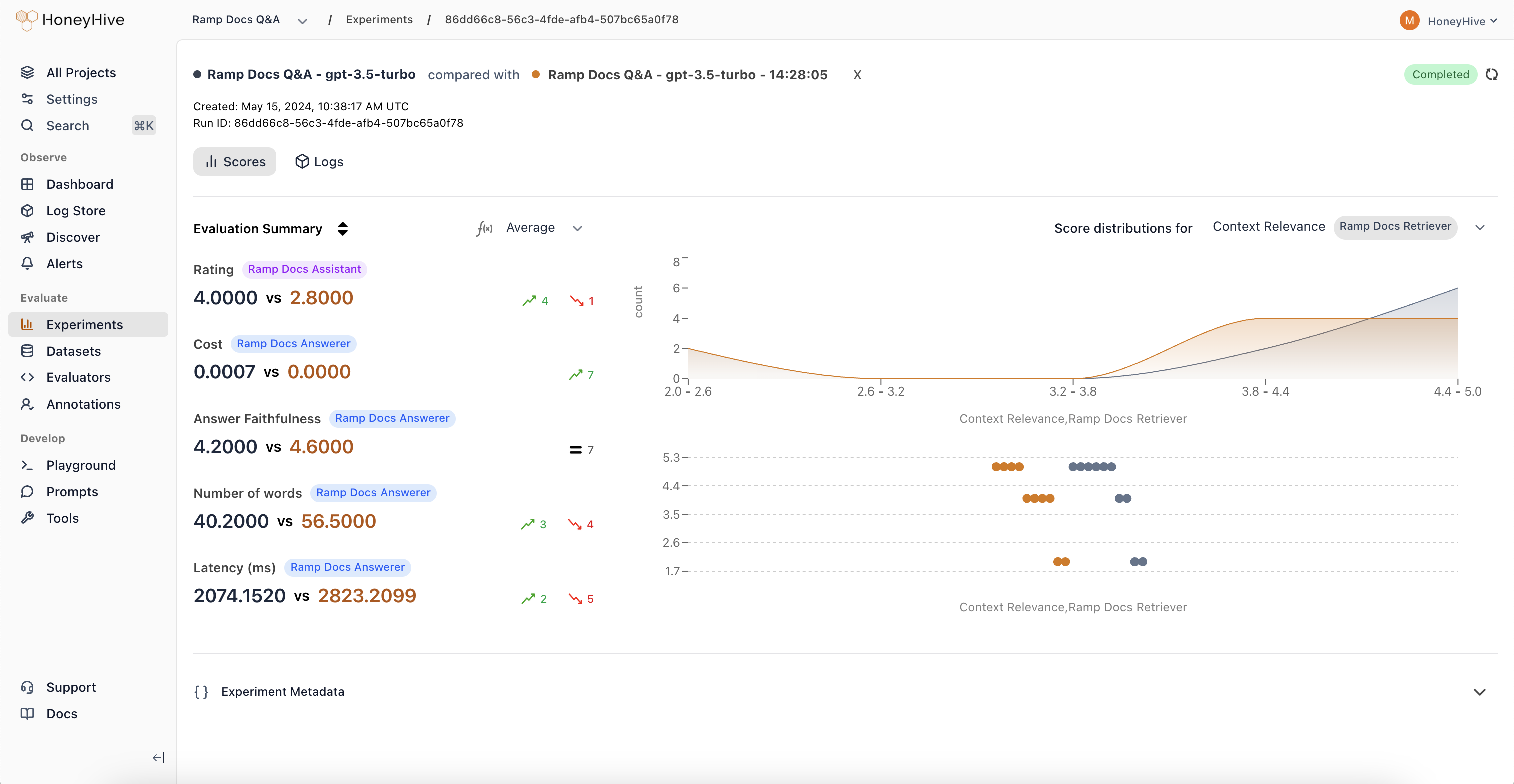
datapoint_id on metadata.
Configuration
A configuration is a generic set of parameters that define the behavior of any component in your application - be that the model, a sub-component, or the application itself.Prompt
Datapoint
A datapoint is a set of input-output pairs (along with any metadata) pertaining to your end-to-end application or a specific agent within your application.
datapoint_id that can be used to track it across different sessions, evaluation runs, and comparisons.
They are also linked to the events that generated them, so you can always trace back to the original data.
Dataset
A dataset is a collection of datapoints that can be used to run evals, fine-tune custom models, or however you see fit. Datasets can be exported and used programmatically in your CI or fine-tuning pipelines. Learn more here.Evaluator
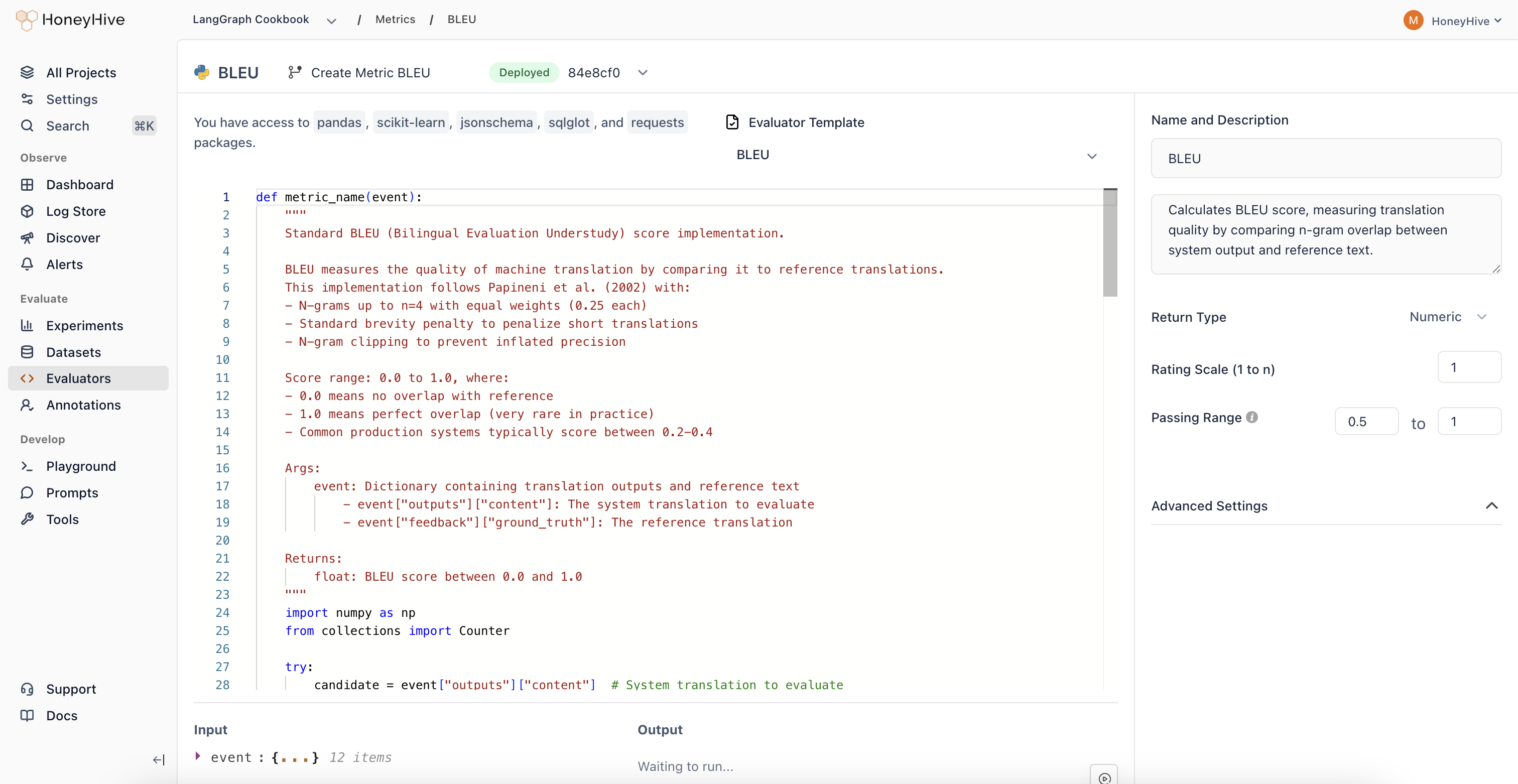
An evaluator is a function (Python or LLM-as-a-judge) that runs over an event to evaluate the performance of your application.