- Want more fine-grained control over input/output features that are logged
- Are using a different run time language than Python or TypeScript
- Already have tracing setup and don’t want to use our tracers
- Have package conflicts with our SDKs
Prerequisites
All of the following strategies assume:- You have already created a project in HoneyHive, as explained here.
- You have an API key for your project, as explained here.
- You have basic familiarity with our data model.
Logging Strategies
For different application types and needs, we have relevant logging strategies. We have created specialized APIs to simplify LLM data ingestion. In the case of open-ended calls to external tools, we have a more generic event logging API. The ideal roadmap for logging your data to HoneyHive is:- Sync LLM ingestion
- Sync LLM + Tool ingestion
- Async LLM + Tool ingestion
- Async LLM + Tool batching
LLM Data Ingestion
If you’d like to track solely the LLM invocations, we provide two ways to manually ingest the logs depending on your run time requirements.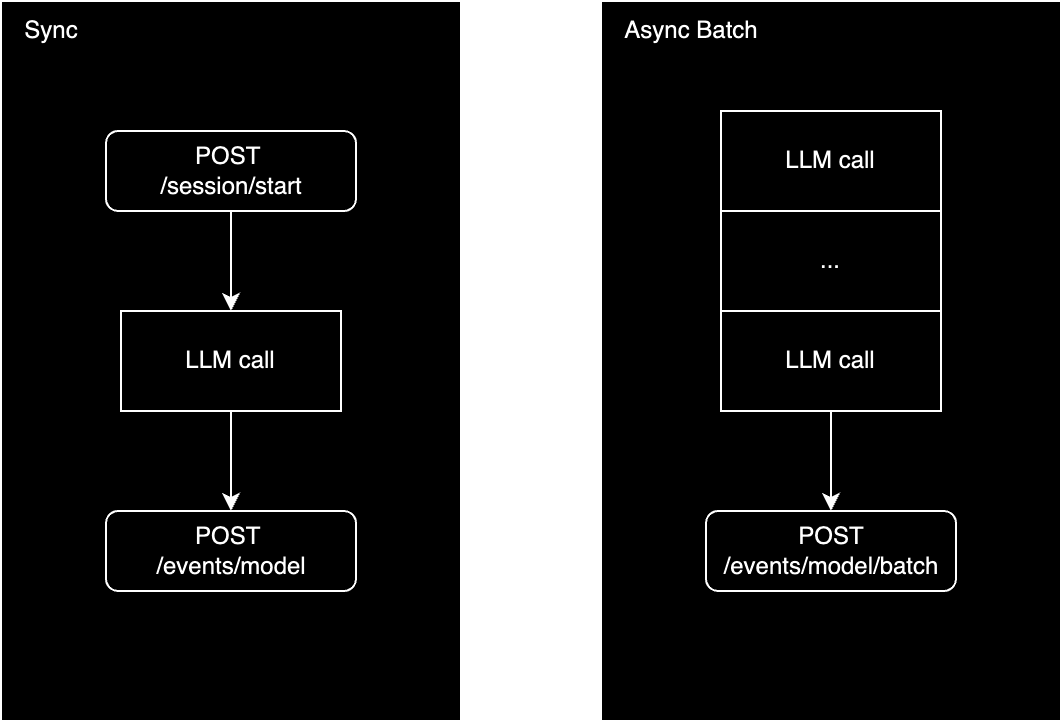
Sync
We normally recommend starting with a synchronous ingestion strategy to logging because it is the easiest to setup. Once your application traffic starts to scale, it’s recommended to switch to an asynchronous ingestion strategy.POST /session/start
If you use
uuidv4 representation as your app’s session ID, feel free to use it as the session ID to make data engineering simpler later.POST /events/model
Async
In an asynchronous ingestion strategy, you wait till the user interaction is completed before logging the data to HoneyHive. You can either send each session’s data right after it completes or collect a larger batch (100-1000) of sessions and flush them regularly. If you already log the session data to a database somewhere, you can use the async batch strategy to import that data into HoneyHive.The model events batch endpoint automatically separates each LLM call into its own session.
POST /events/model/batch
External Tool Data Ingestion
If you’d like to track external tool calls (like vector DBs, function calls, etc) along side the LLM invocations, we follow a similar idea as the above LLM ingestion distinction. We highly recommend reading our Data Model to understand the data you need to log and how to structure it.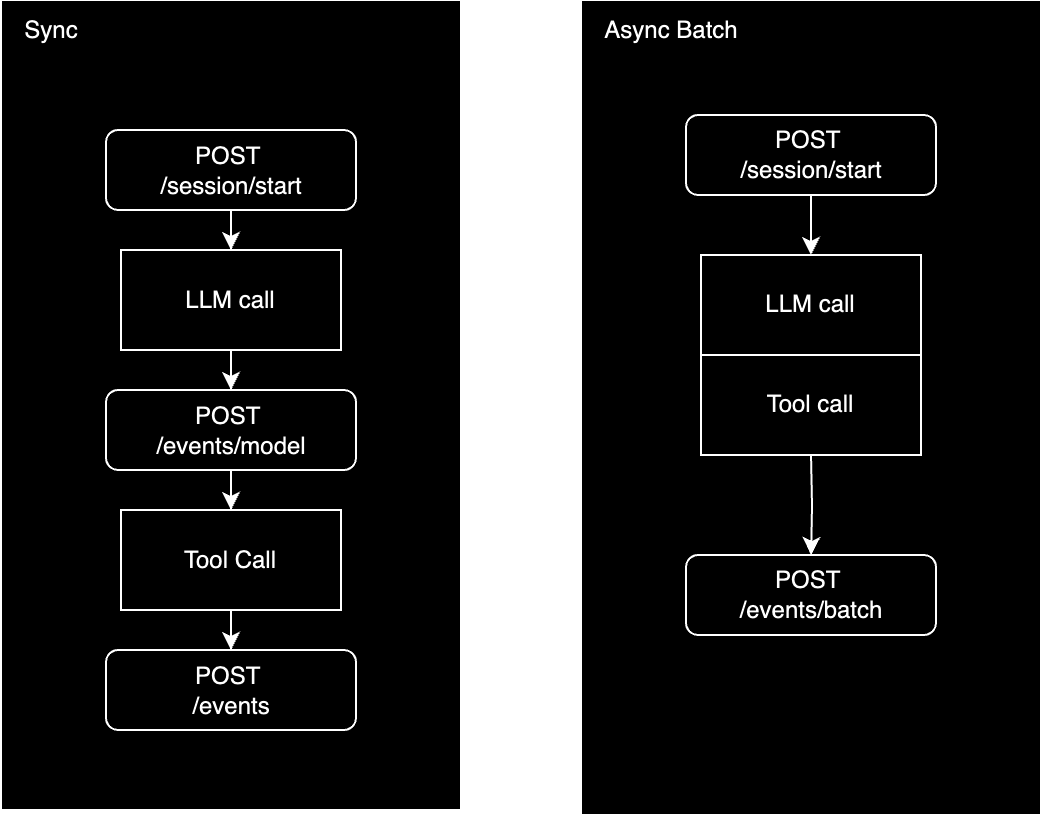
Sync
The synchronous ingestion strategy for tool calls is similar to the LLM ingestion strategy.POST /session/start
session_id that’s returned to link the future events to the same session.
POST /events
Async
The asynchronous ingestion strategy for tool calls is again similar to the LLM ingestion strategy with the key difference of using ourPOST /events instead of POST /events/model.
You can either send each session’s data right after it completes or collect a larger batch (100-1000) of sessions and flush them regularly.
POST /events/batch
is_single_session.
- If set to
true, the events in the batch will be grouped into a single session. - If set to
false, HoneyHive only refers to thesession_idon the event to decide which session the event belongs to.
false so each event becomes its own session (or grouped into the session according to its session_id).
If you want to group events into chain events, refer to the chain events section on our Data Model page.