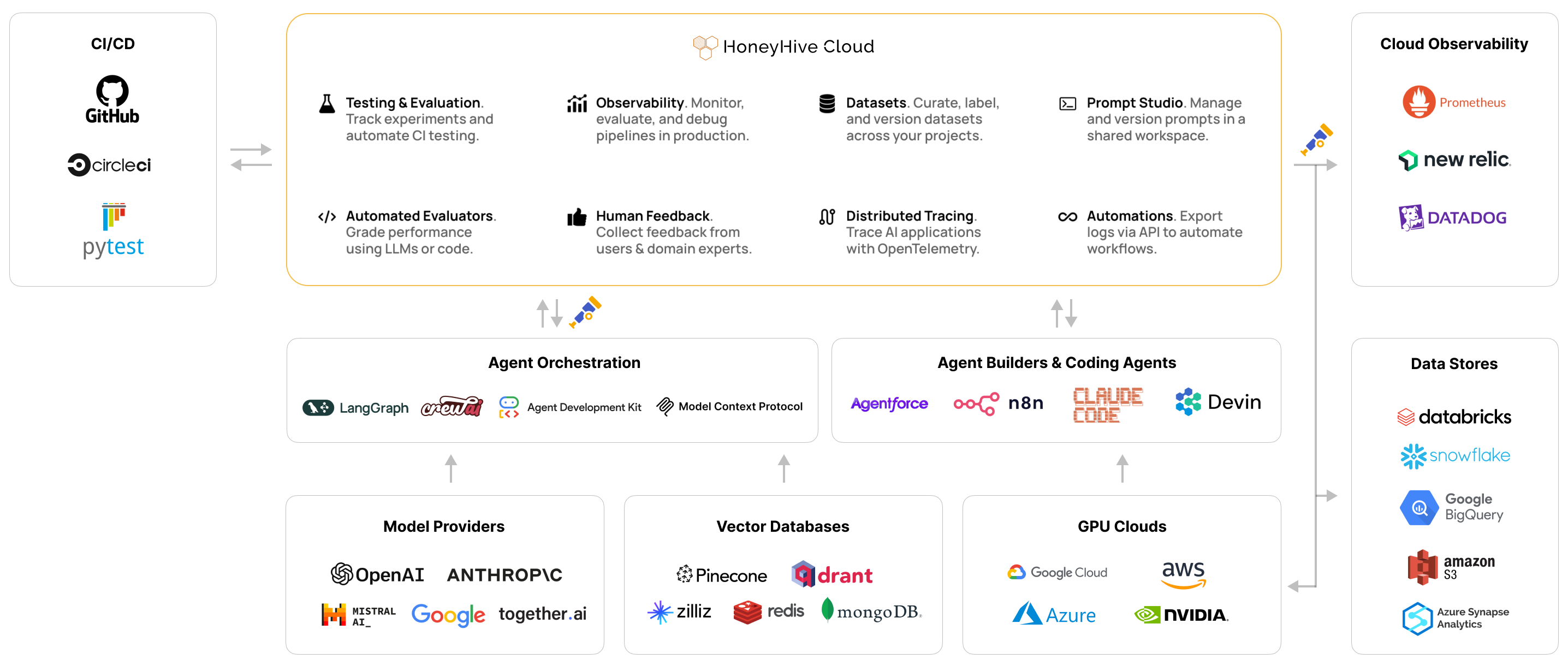
HoneyHive is an AI observability and evaluation platform for tracing, testing, monitoring, and improving agents from development through production.
HoneyHive helps you trace, evaluate, monitor, and improve AI agents from development through production. Start with the tracing quickstart to capture your first session, then run an offline experiment to measure quality before you deploy.
Start Tracing
Instrument your first agent and capture traces in 5 minutes.
Run Your First Evaluation
Set up an experiment and evaluate your agent programmatically.
HoneyHive follows an Evaluation-Driven Development (EDD) workflow, similar to TDD in software engineering, where evaluation guides every stage of agent development. Production monitoring feeds datasets and experiments that drive the next iteration.
1
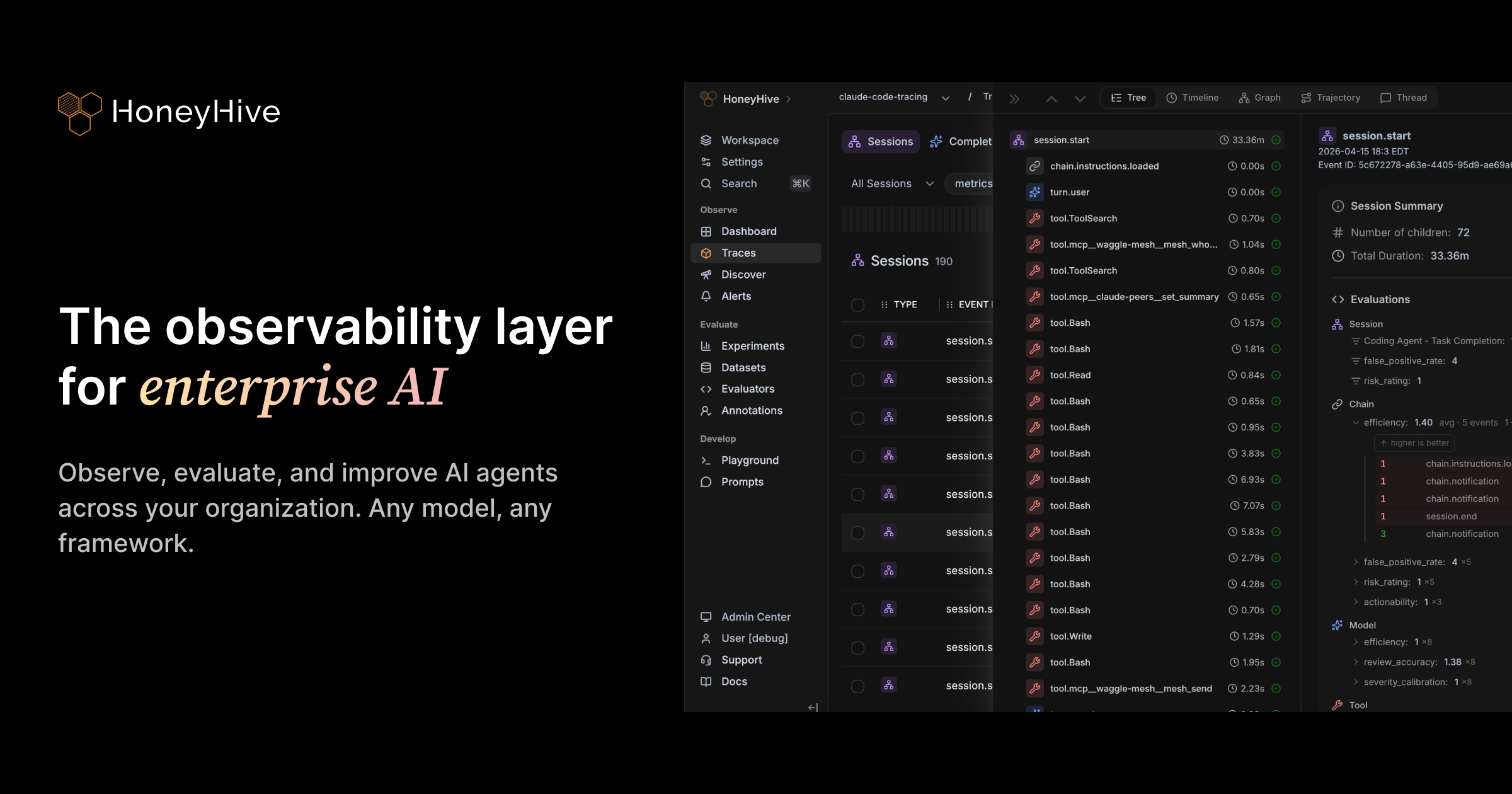
Production: Observe and Evaluate
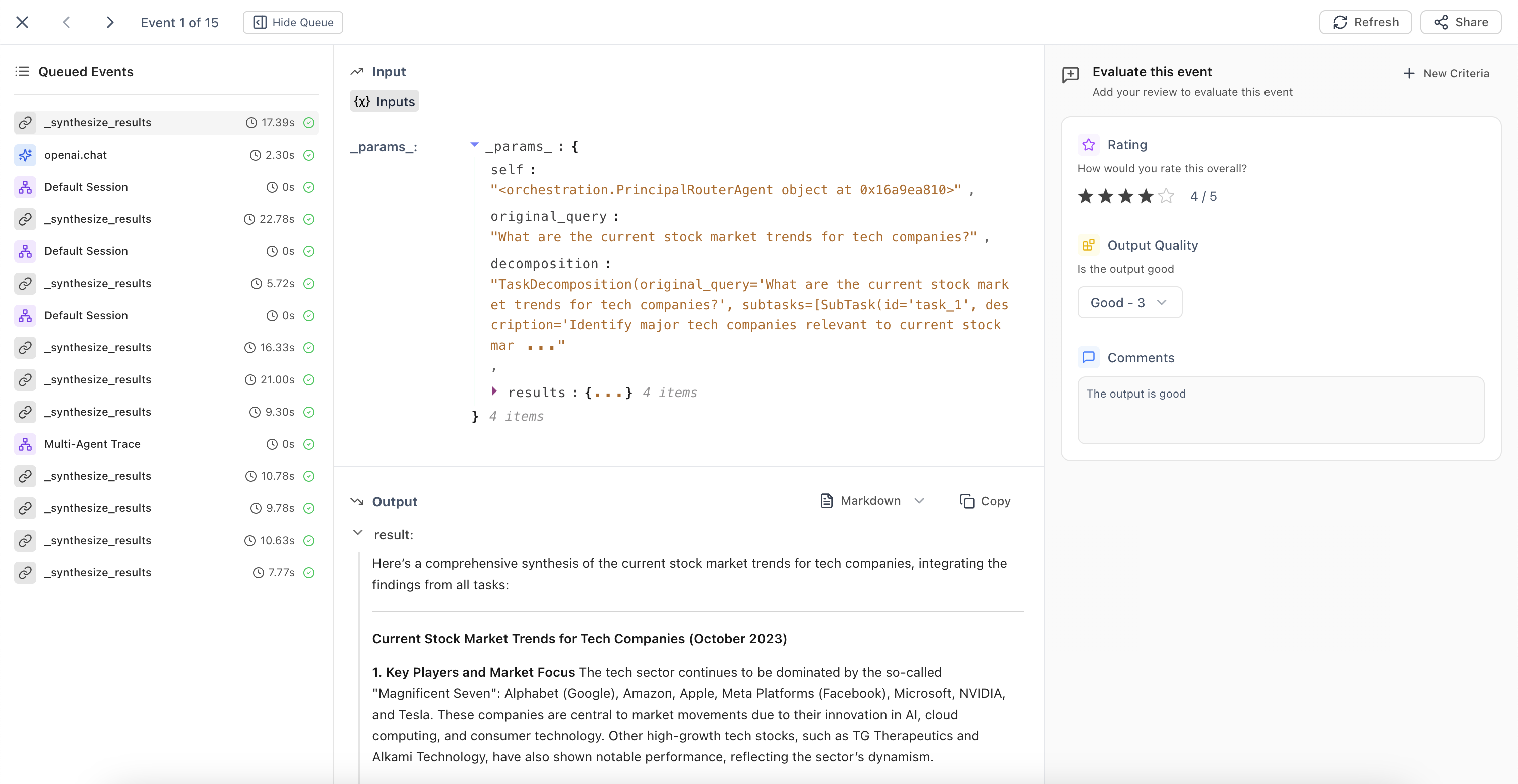
Instrument your application with distributed tracing to capture every interaction. Collect traces, user feedback, and quality metrics from production. Run online evals to surface edge cases at scale, and set up alerts to catch failures or metric drift.
Traces
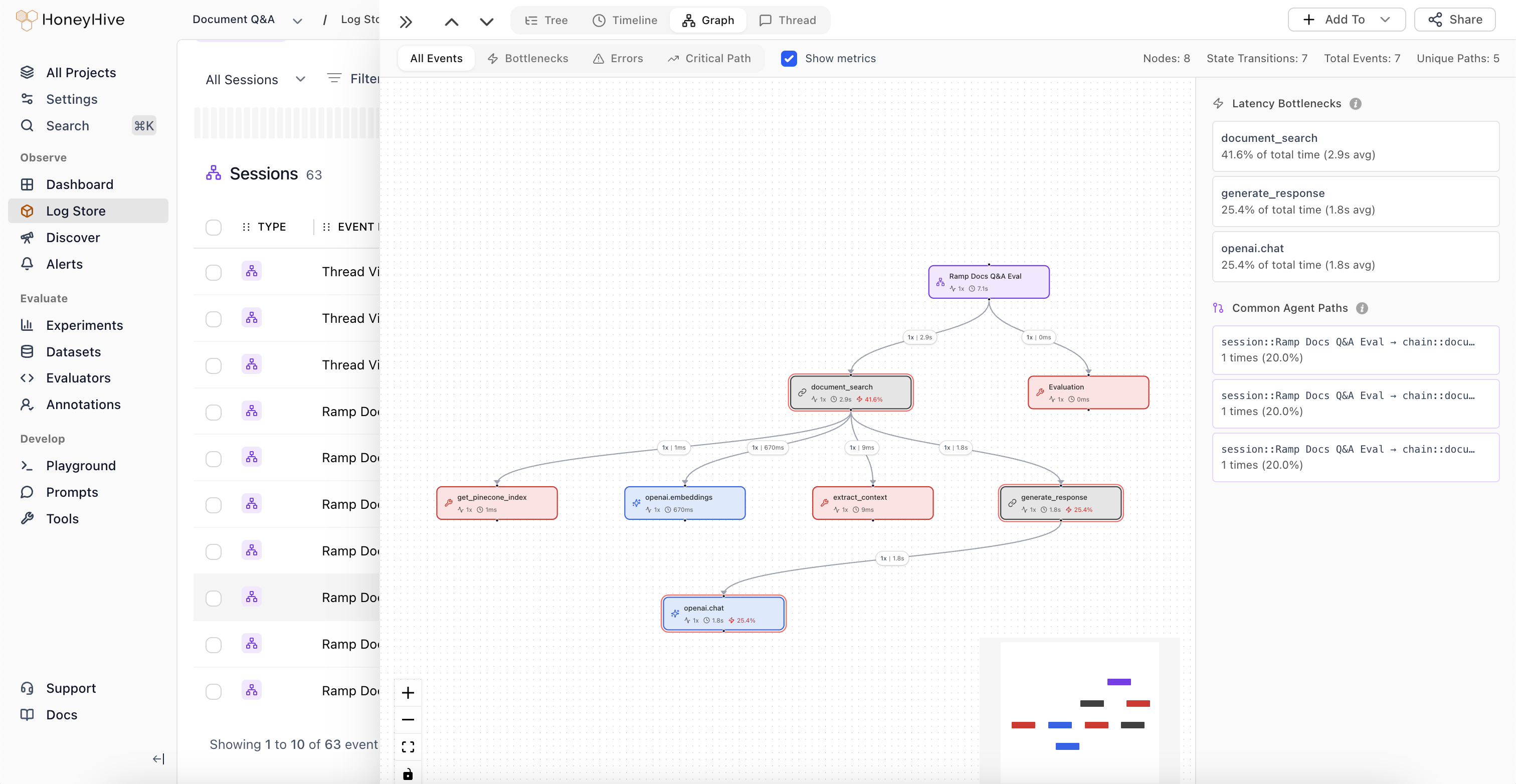
Agent Graphs
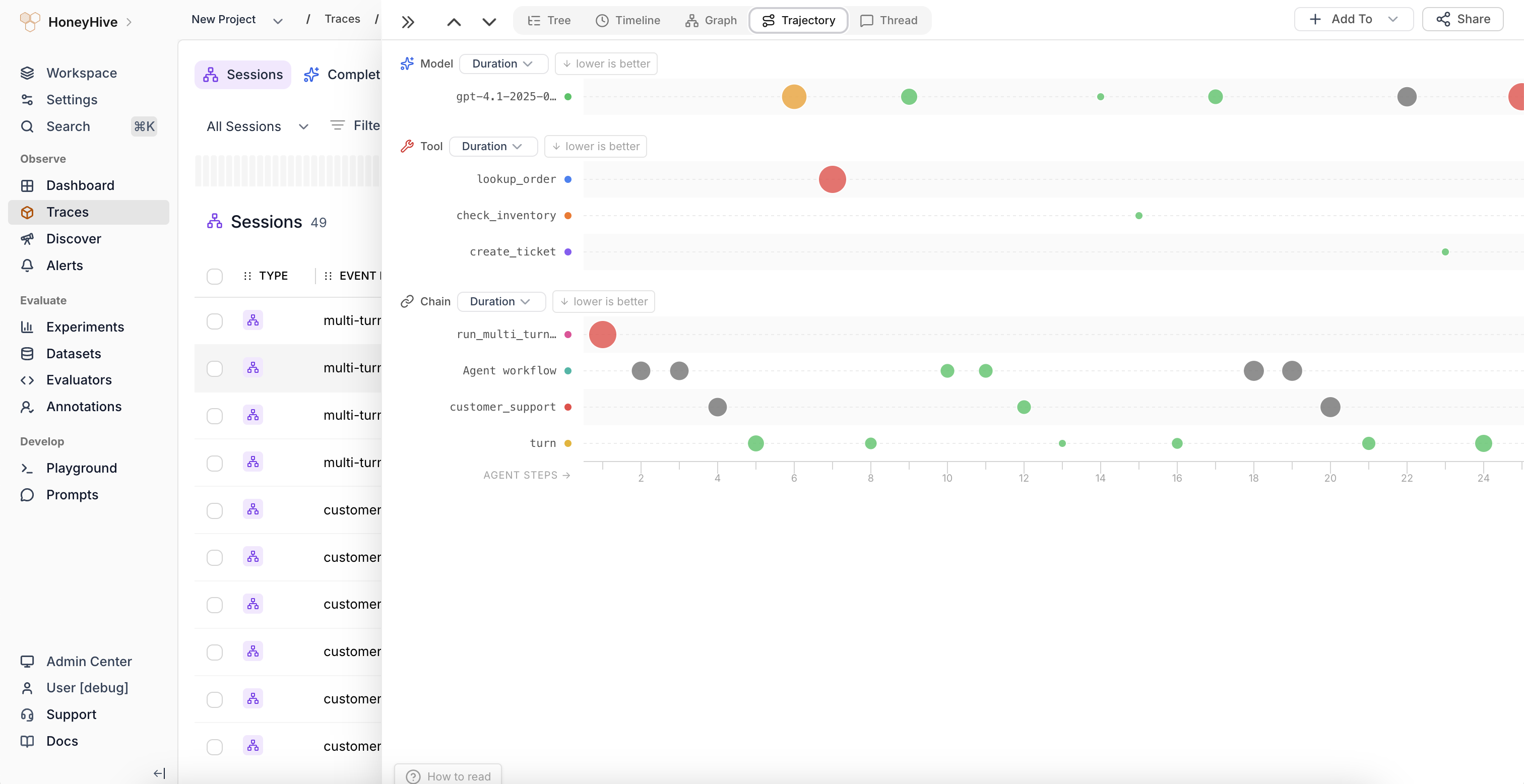
Trajectories
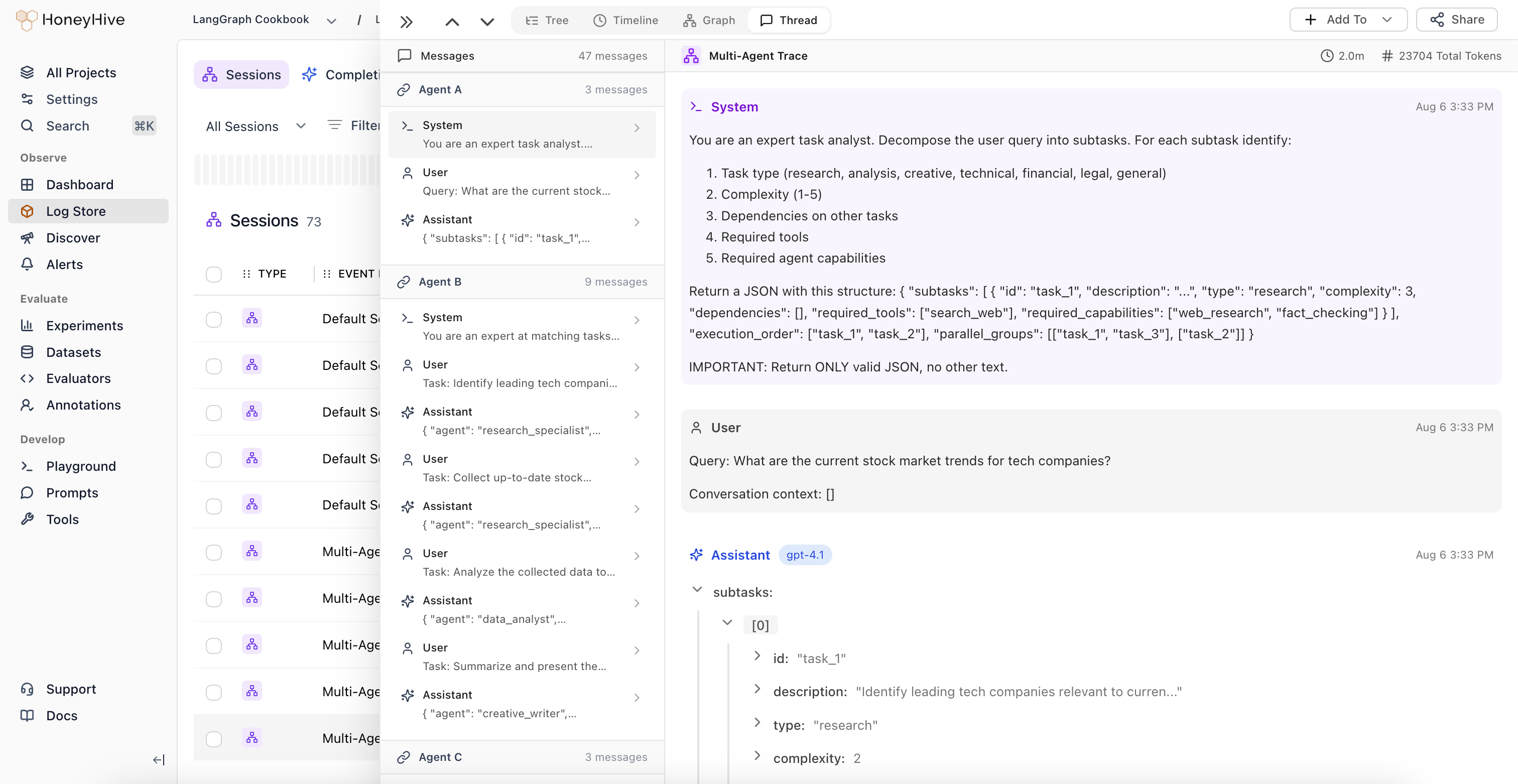
Threads
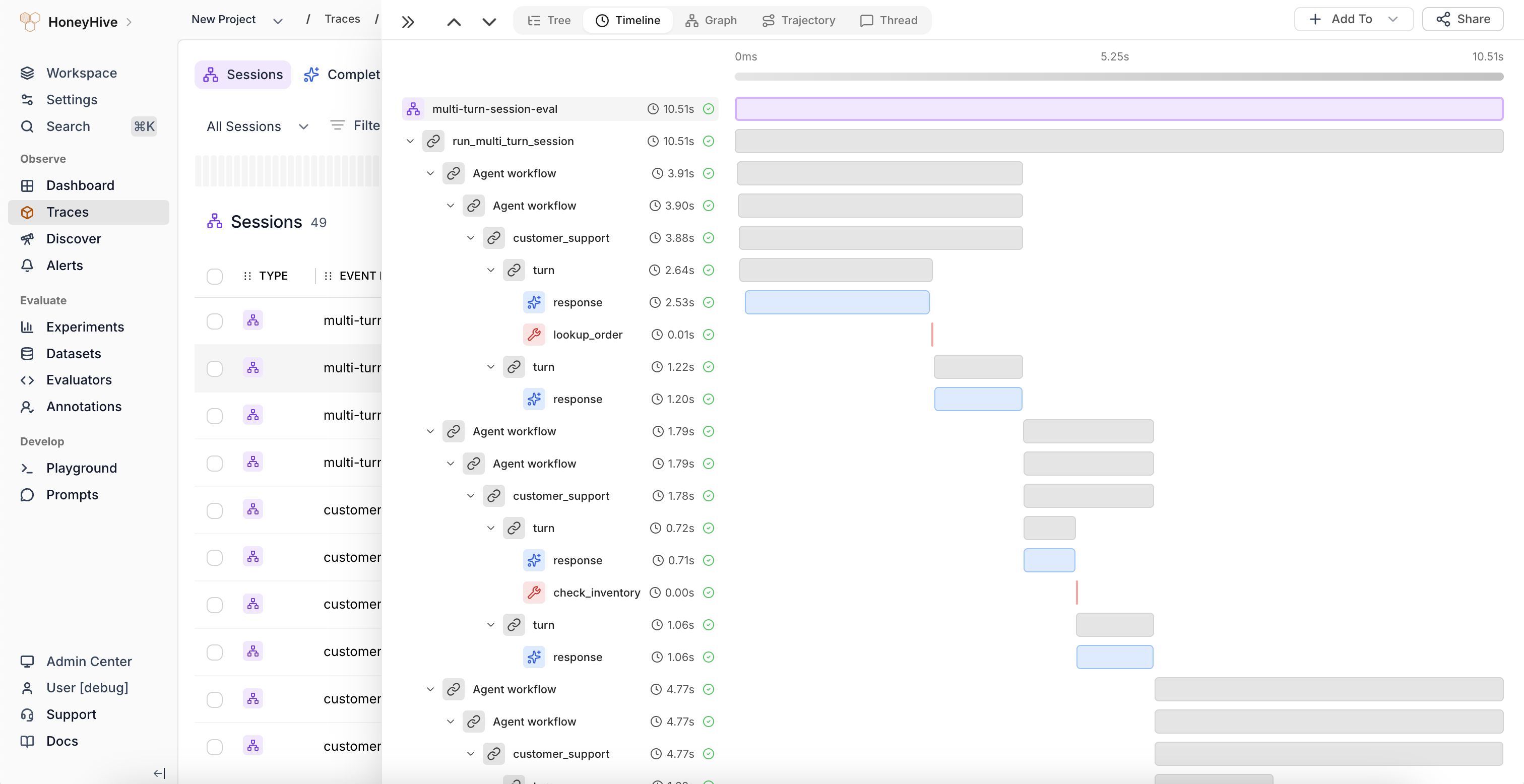
Timeline View
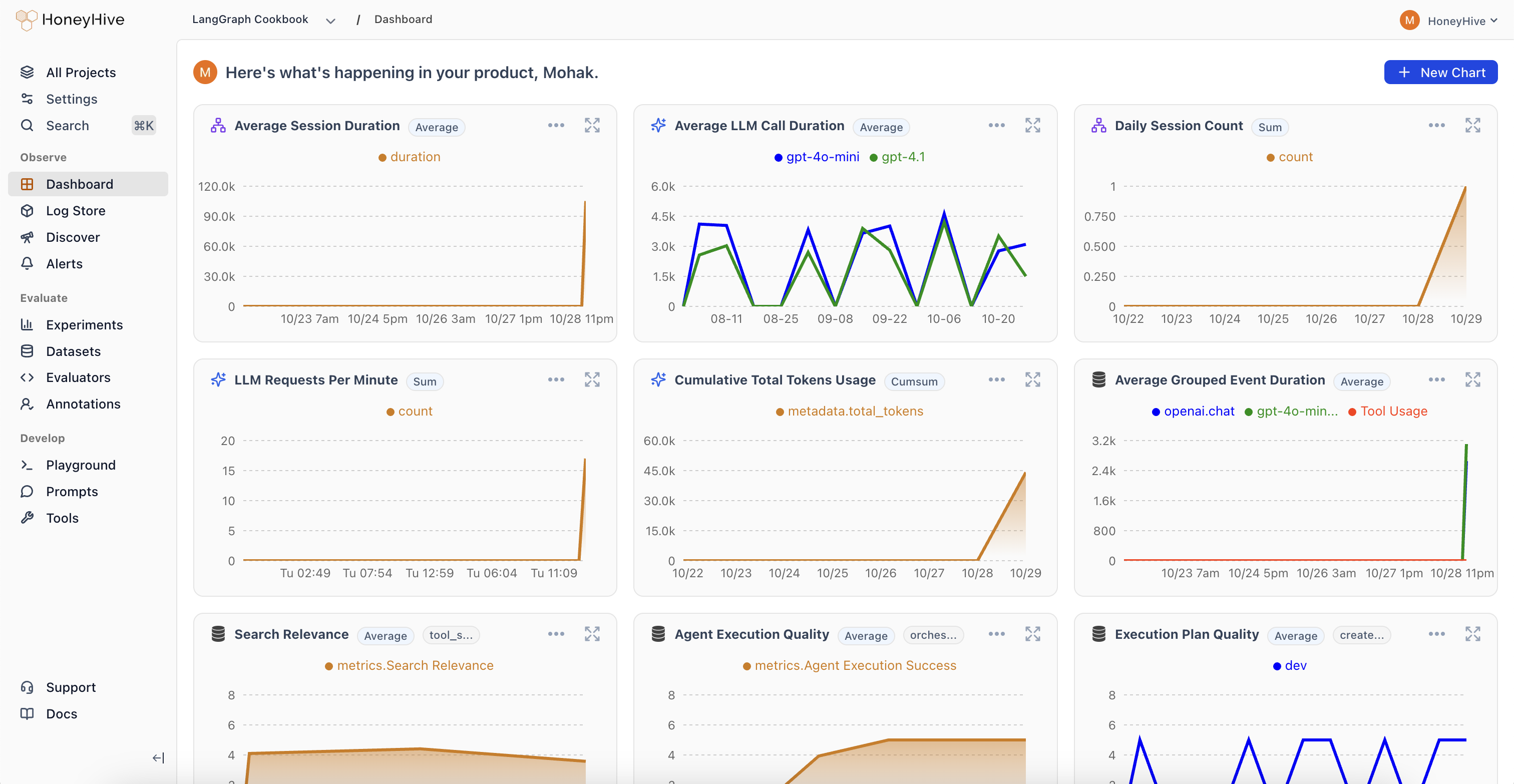
Dashboard
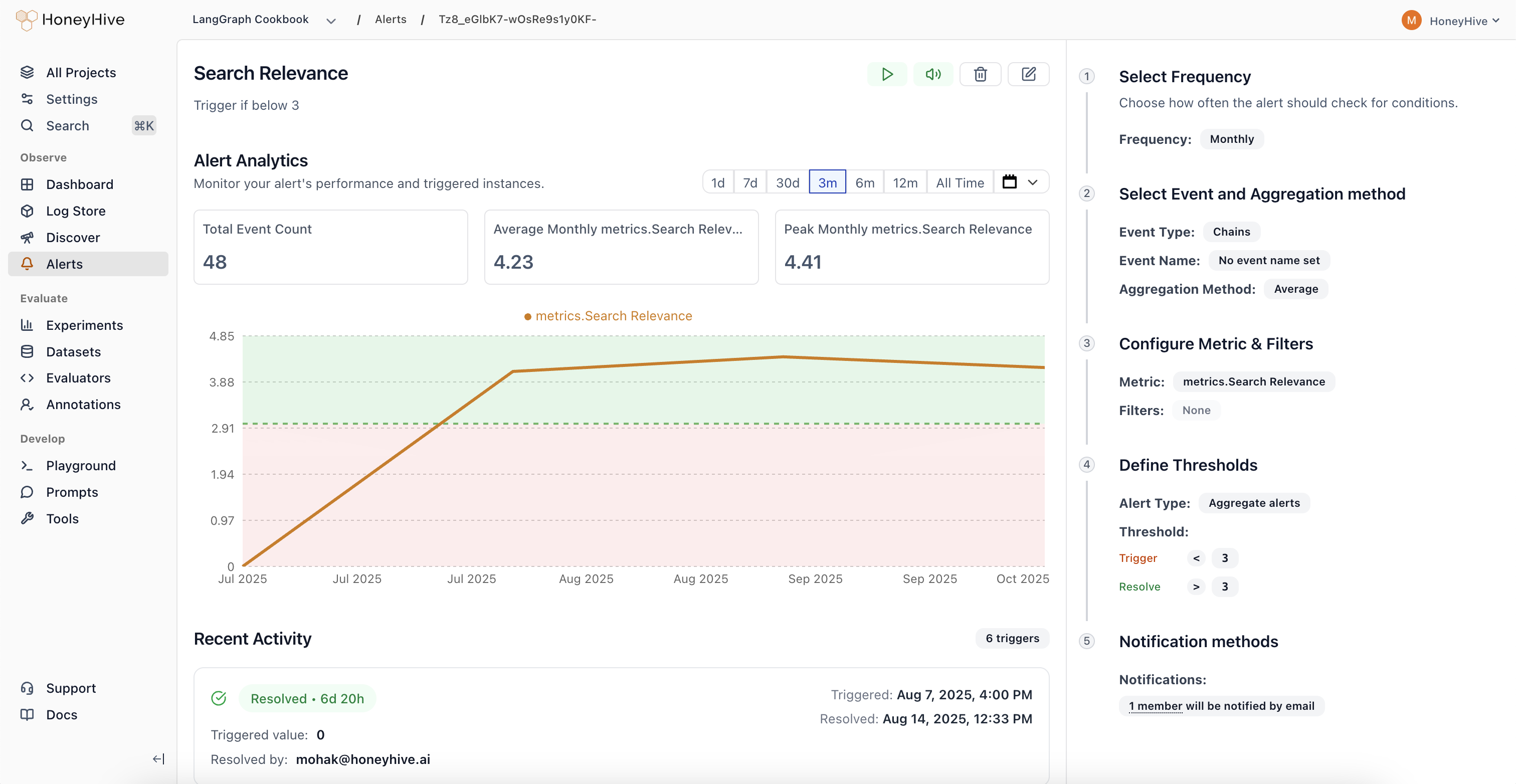
Alerts
Inspect every LLM call, tool invocation, and chain step in a structured execution log.
Visualize agentic workflows as interactive graphs showing how components connect and where execution flows.
Spot loops, stuck steps, and outliers in long agent sessions as bubbles sized by duration, cost, metrics, feedback, or metadata values.
Follow a session across multiple sub-agents in a single chronological thread, including internal messages and context propagation.
Identify latency bottlenecks with a chronological breakdown of every operation in a trace.
Track cost, latency, and success rates with customizable charts and filters.
Get notified when quality drops or errors spike so you can respond before users are affected.
2
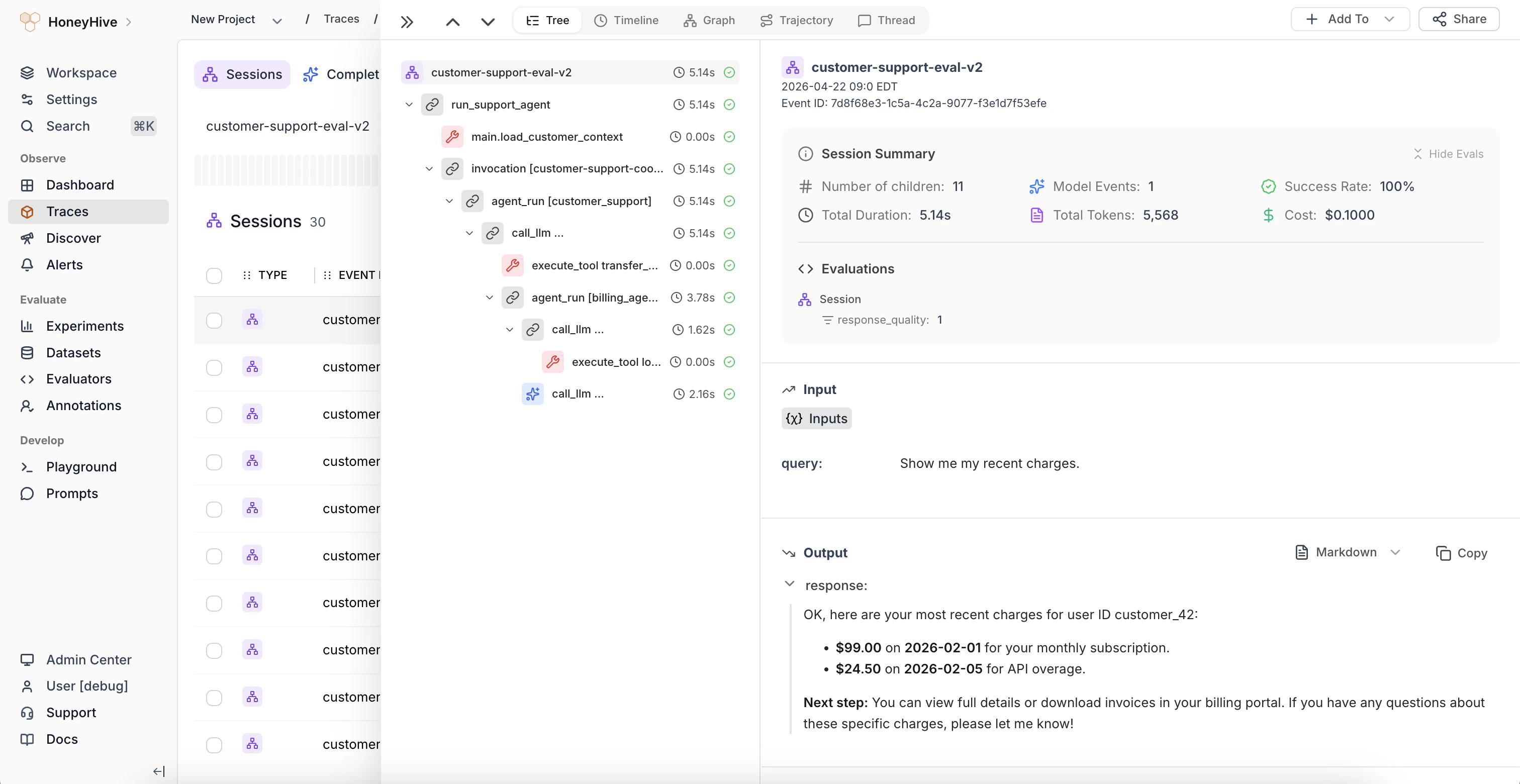
Testing: Curate Datasets & Run Experiments
Turn failing production traces into curated test datasets. Run experiments to measure the impact of your changes, track regressions over time, and gate releases in CI.
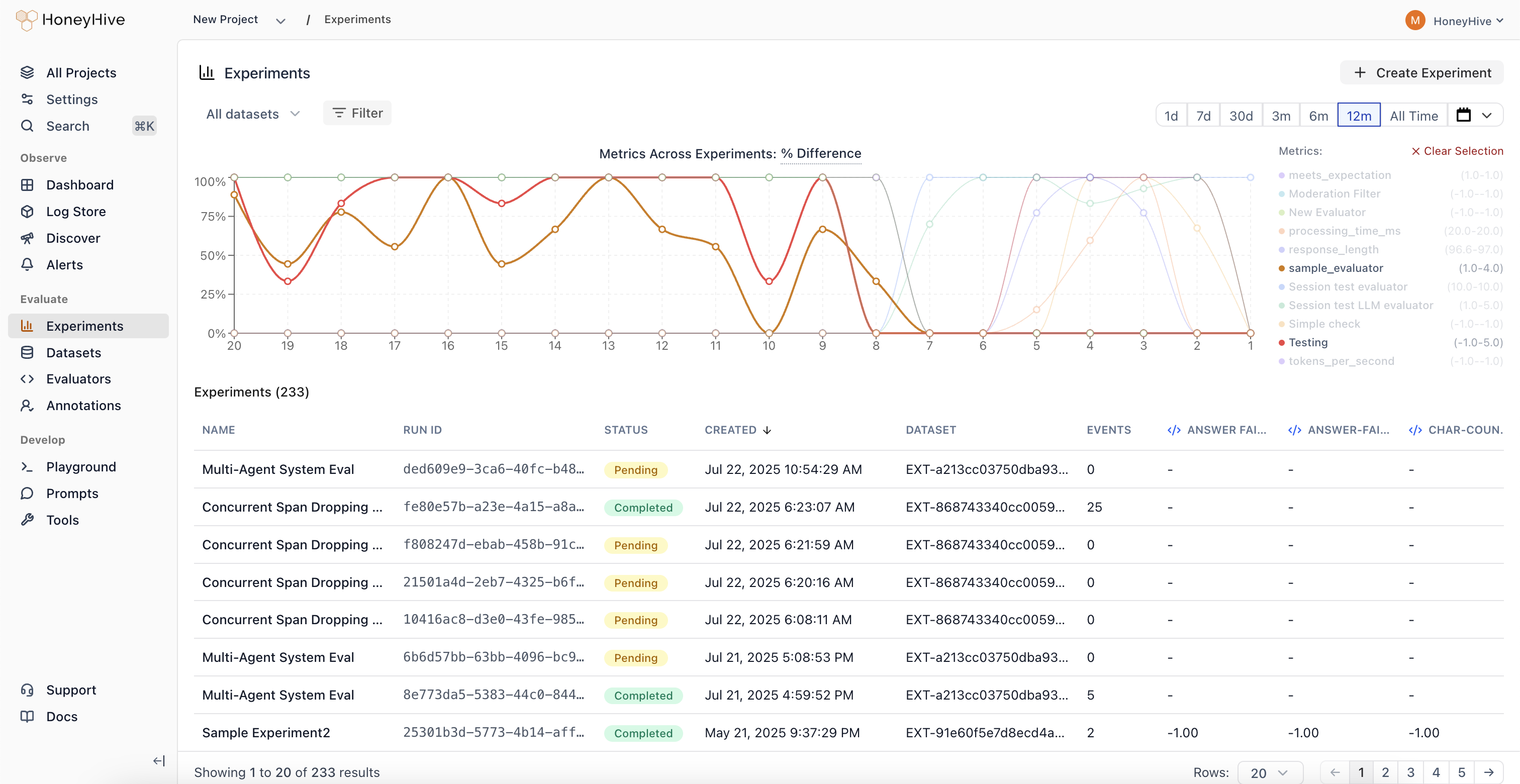
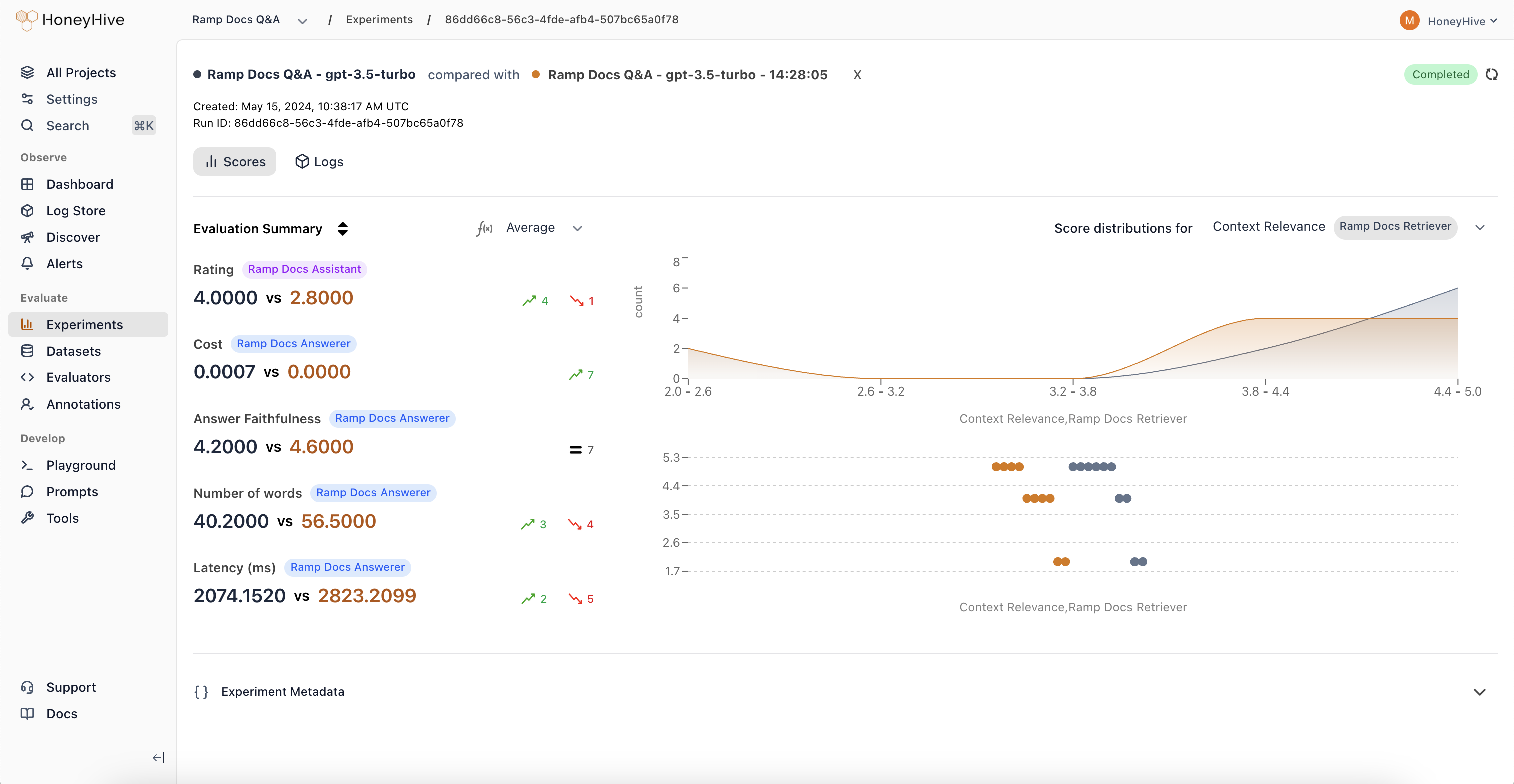
Experiments
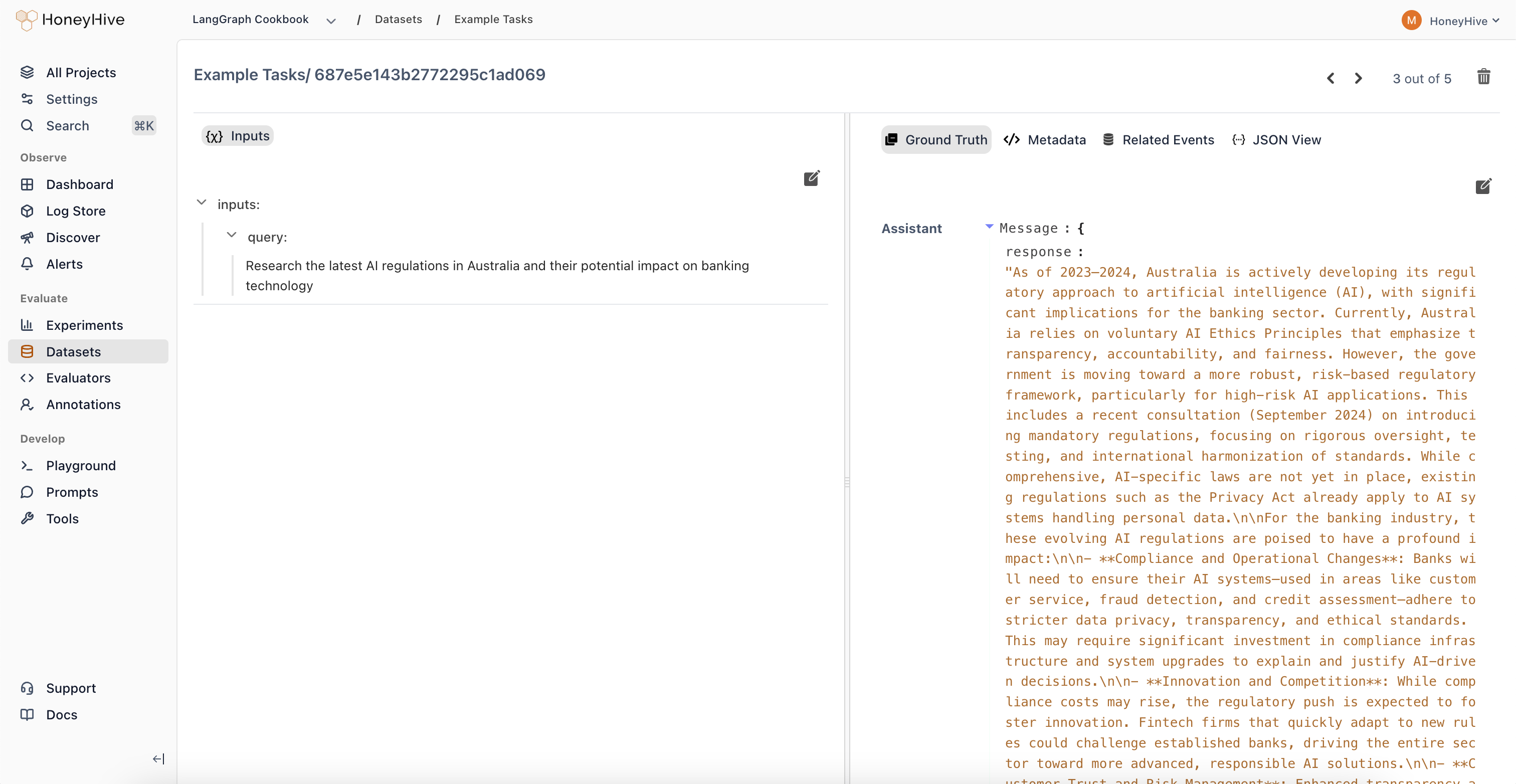
Datasets
Regression Tests
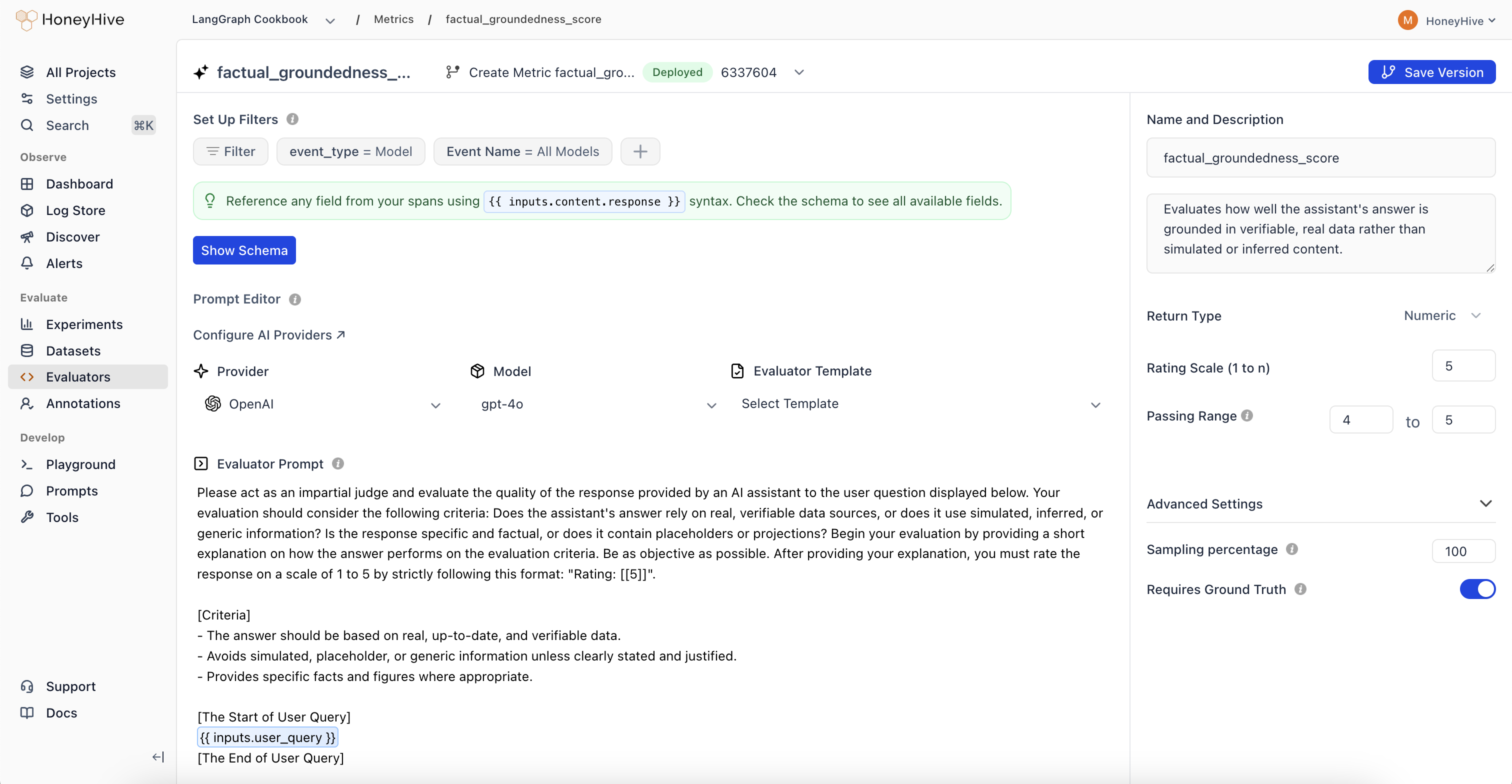
LLM Evaluators
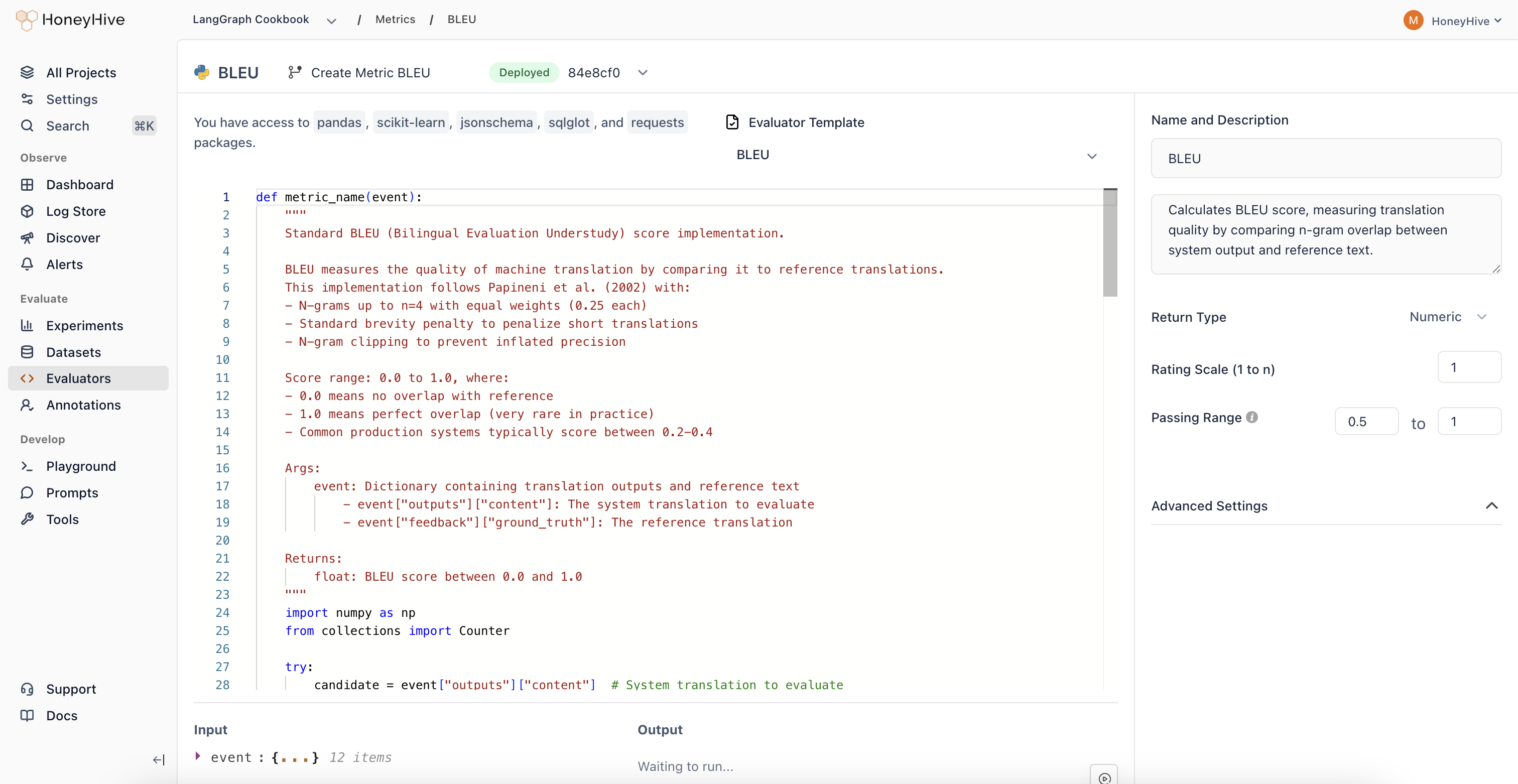
Code Evaluators
Annotation Queues
Compare prompts, models, or configurations side-by-side to see which changes improve performance.
Build test sets from production failures and edge cases to cover real-world scenarios.
Verify that new changes don’t break existing behavior by running evaluations on every update.
Use AI to assess response quality, accuracy, and safety at scale without manual review.
Write custom Python evaluation logic for domain-specific metrics that LLMs can’t judge reliably.
Collect expert judgments on agent outputs to build ground truth labels and improve automated evaluators.
3
Development: Iterate on Prompts
Use evaluation results to guide changes. Iterate on prompts, test new models, and optimize your application based on what the data shows. Validate changes against curated datasets before deploying.
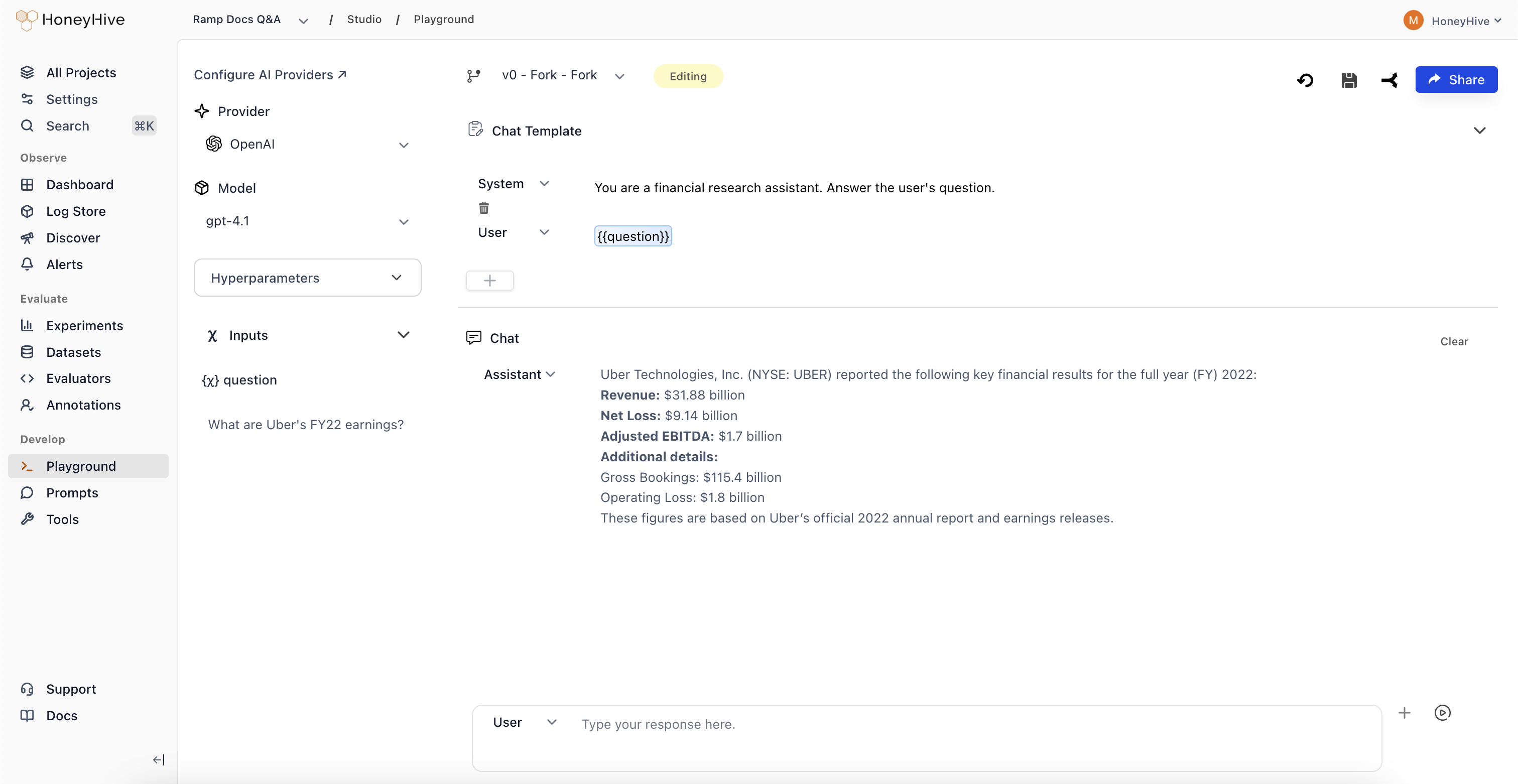
Playground
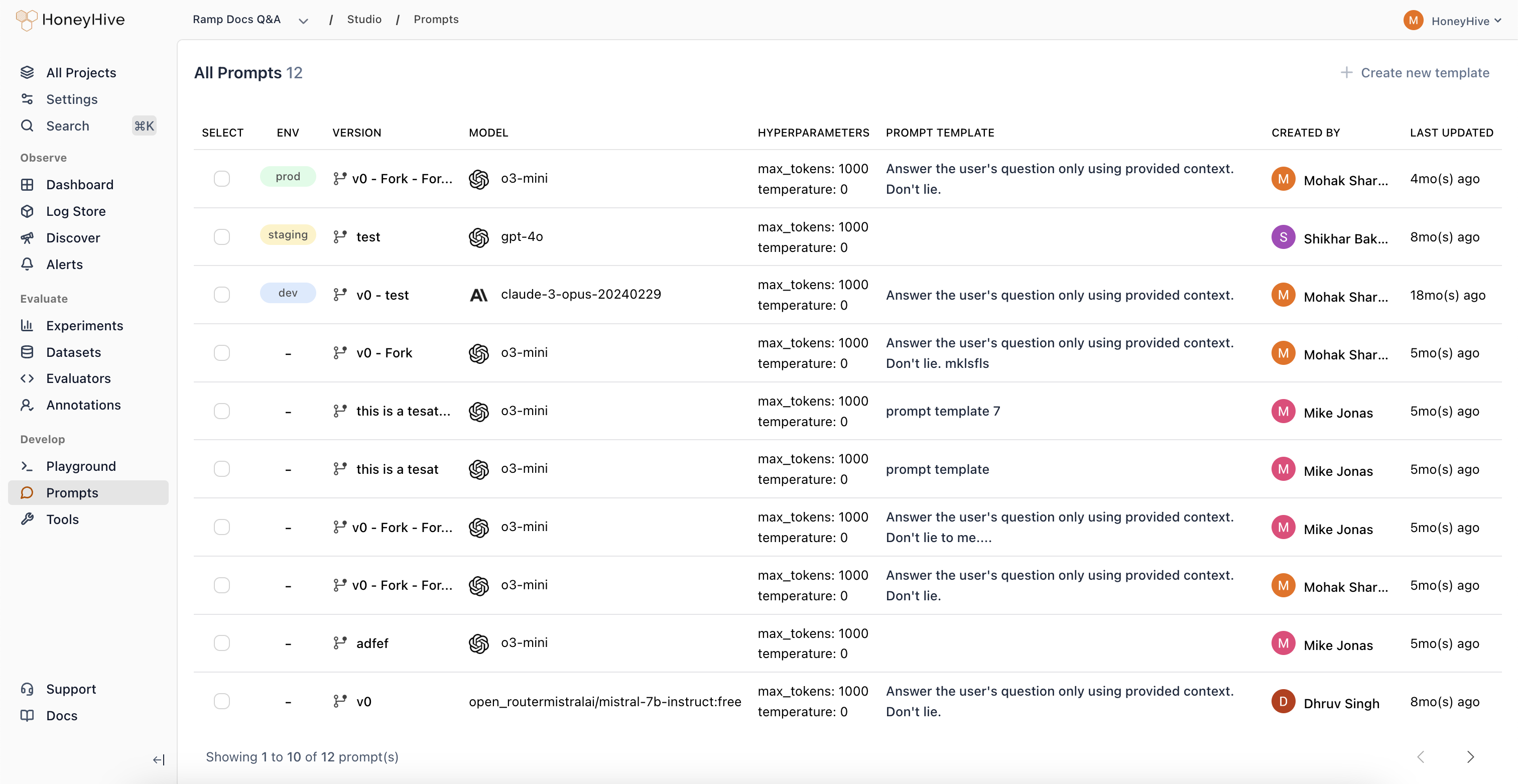
Prompt Management
Test prompt variations and model configurations with instant feedback before committing to code.
Version and deploy prompts centrally so your team can iterate without code changes or redeployments.
4
Repeat: Continuous Improvement
Deploy improvements and continue the cycle. Each iteration builds on production data, creating a flywheel of improvement that makes your AI systems more reliable over time.
HoneyHive is built on OpenTelemetry, so it works across models, frameworks, and runtimes with no vendor lock-in. See tracing concepts for how sessions, events, and OTel fit together.
Model Agnostic
Works with OpenAI, Anthropic, Bedrock, open-source models, and more.
Framework Agnostic
Native support for LangChain, CrewAI, Google ADK, AWS Strands, and more.
Runtime Agnostic
Trace any runtime - Lambdas, Kubernetes, Bedrock AgentCore, and more.
Bring Your Own Instrumentor
HoneyHive supports official OTEL GenAI, OpenLLMetry, and OpenInference semantic conventions.

.png)