- Add session-level context (environment, app version)
- Add metadata directly to LLM spans
- Add metadata to parent spans for complex pipelines
Setup with Session Context
First, initialize the tracer and set session-level context that applies to ALL traces: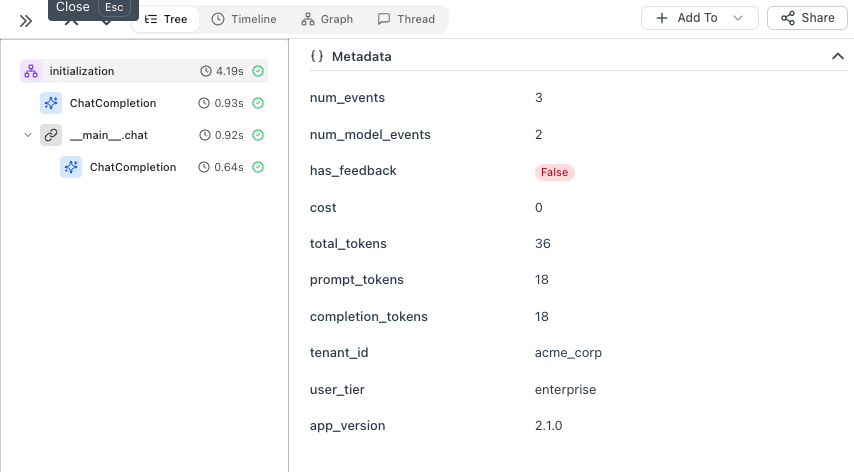
Session metadata appears on all traces
Option 1: Enrich LLM Spans Directly
The simplest way to add per-call metadata - useusing_attributes from OpenInference:
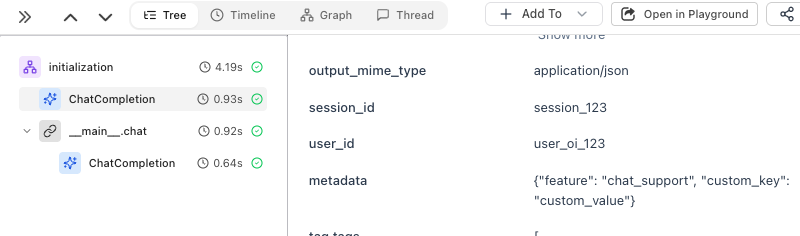
Metadata attached directly to the LLM span
Option 2: Create a Parent Span
When you have multiple steps (retrieval, processing, LLM calls), use@trace to create a parent span that groups them:
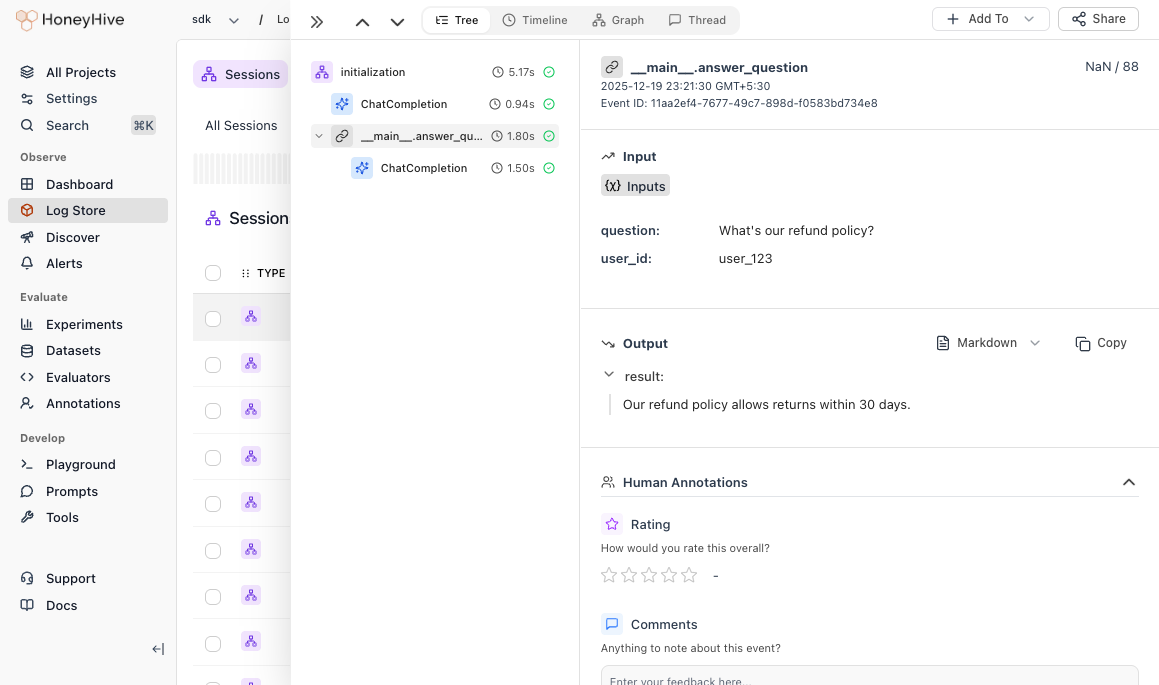
Parent span captures business inputs/outputs, LLM call nested inside
When to Use Which
Best Practices
DO: Add user IDs, feature names, environment. Use descriptive keys (user_id not uid).
DON’T: Include passwords, API keys, or PII. Keep fields under 1KB.
What’s Next?
Run Your First Experiment
Set up datasets and run evaluations
Enrichment Reference
Detailed guide for advanced enrichment patterns