How to Compare Runs
- Go to Experiments in the sidebar
- Select an experiment run to view its details
- Click compared with and select another run from the dropdown
- The view updates to show side-by-side comparison
Runs are comparable when they share common datapoints (matched by
datapoint_id). For best results, run experiments against the same HoneyHive dataset.Comparison Features
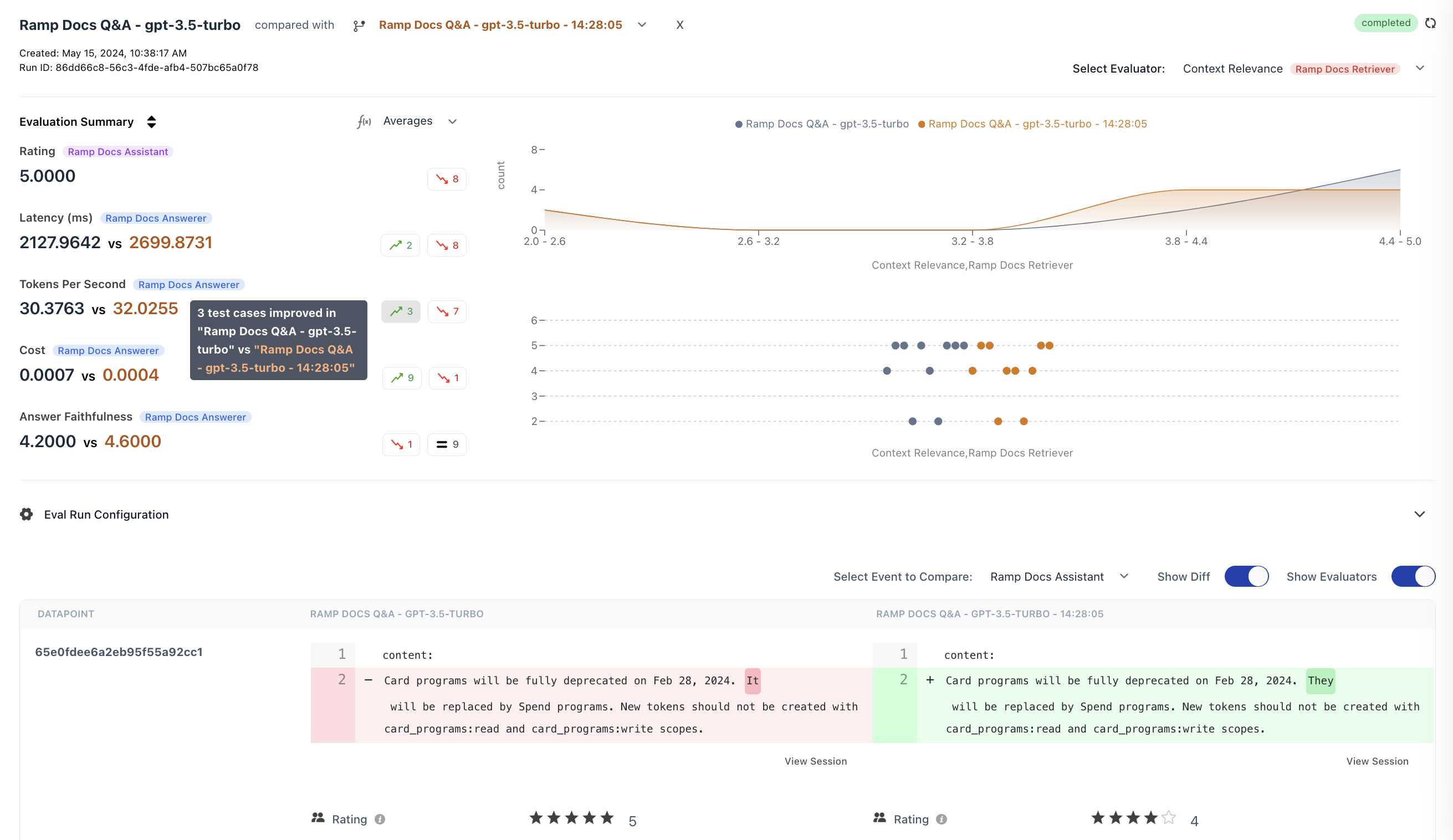
Aggregated Metrics
View aggregate scores for each metric across both runs. The summary highlights improved and regressed counts, so you can see at a glance which run performed better on each metric.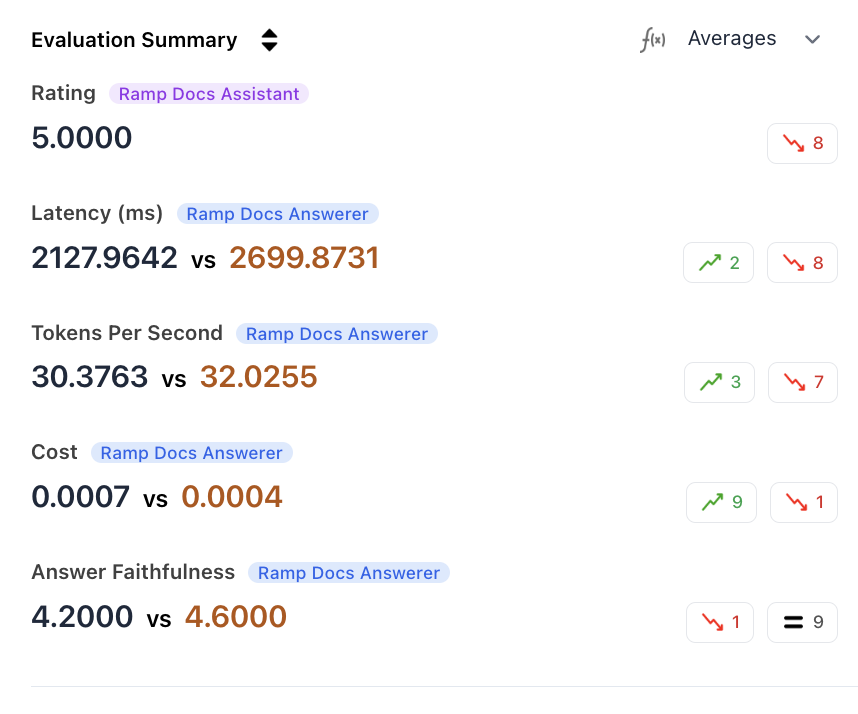
Metric Distribution
Analyze how scores are distributed across datapoints. This helps identify whether improvements are consistent or driven by outliers.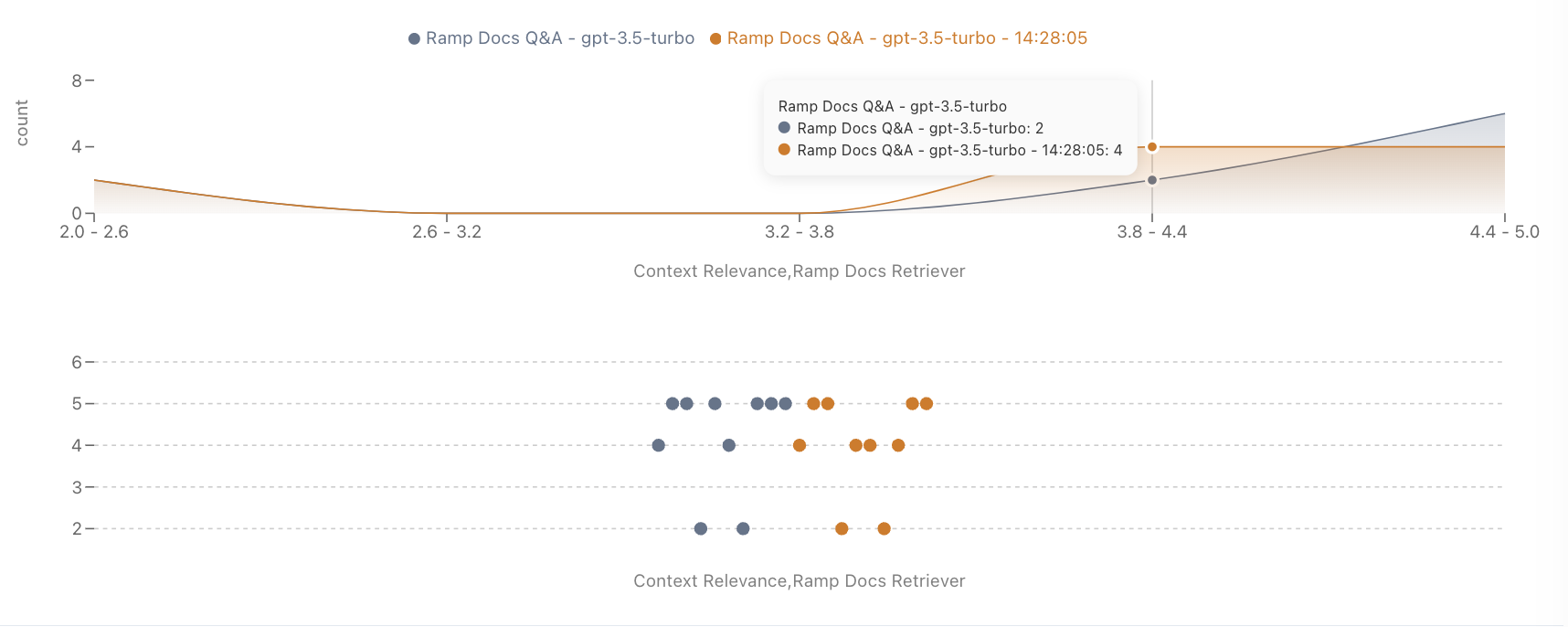
Improved/Regressed Filtering
Filter the datapoint table to show only cases where performance improved or regressed on a specific metric.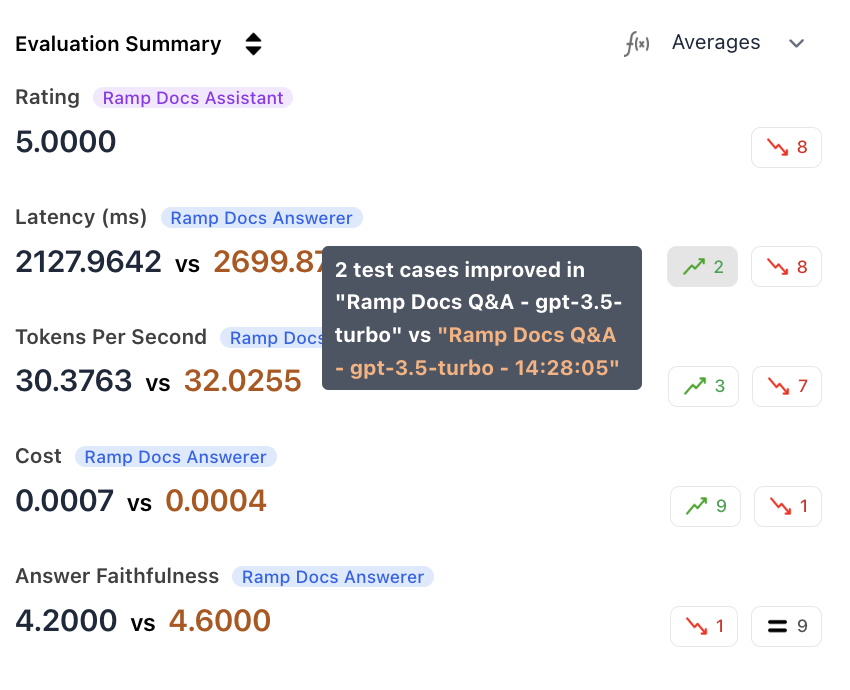
Output Diff Viewer
Toggle Diff mode to see side-by-side outputs for each datapoint, with differences highlighted. This helps you understand exactly how outputs changed between runs.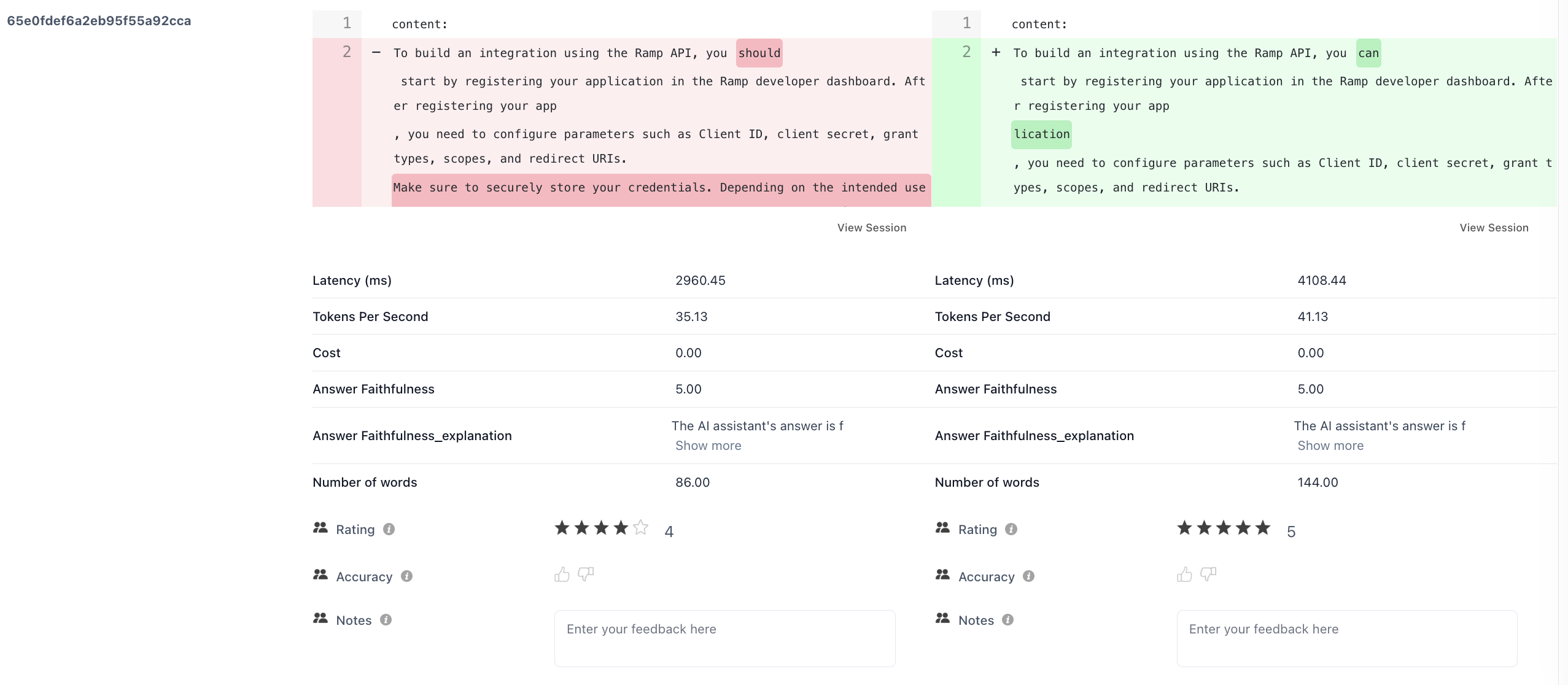
Step-Level Comparisons
For multi-step traces, compare metrics at each individual step using the Viewing Event dropdown. This shows how changes affect specific stages of your pipeline.Programmatic Comparison
Usecompare_runs() to analyze differences in code:
Working with Results
Thecompare_runs() function returns a RunComparisonResult object. Key properties include common_datapoints, new_only_datapoints, old_only_datapoints, and metric_deltas. Use the helper methods to quickly identify changes:
list_improved_metrics()- metric names where at least one datapoint improvedlist_degraded_metrics()- metric names where at least one datapoint degradedget_metric_delta(name)- detailed delta for a specific metric, includingold_aggregate,new_aggregate,improved_count,degraded_count, and lists of affected datapoint IDs
Best Practices
Related
Run Your First Experiment
Tutorial with step-by-step comparison example
Run with HoneyHive Datasets
Reuse the same HoneyHive dataset across comparison runs
CI Regression Detection
Use
compare_runs() in CI to block PRs on metric regressionsEvaluation Framework
Understand the underlying evaluation architecture