Evaluation-Driven Development Workflow
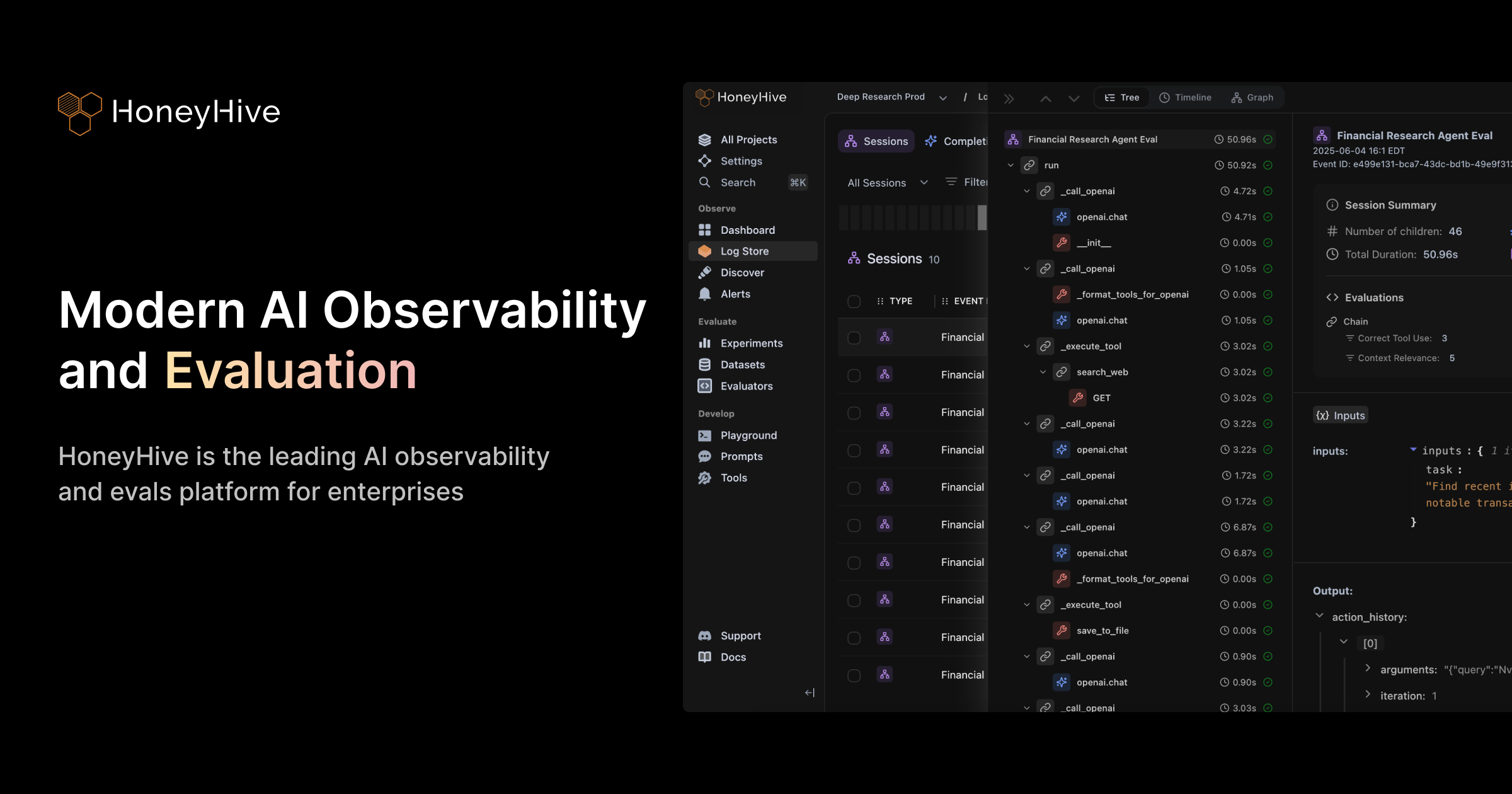
Traditional AI development is reactive—you build, deploy, and hope for the best. HoneyHive enables a systematic Evaluation-Driven Development (EDD) approach, similar to Test-Driven Development in software engineering, where evaluation guides every stage of the Agent Development Lifecycle.Production: Observe and Evaluate Agents
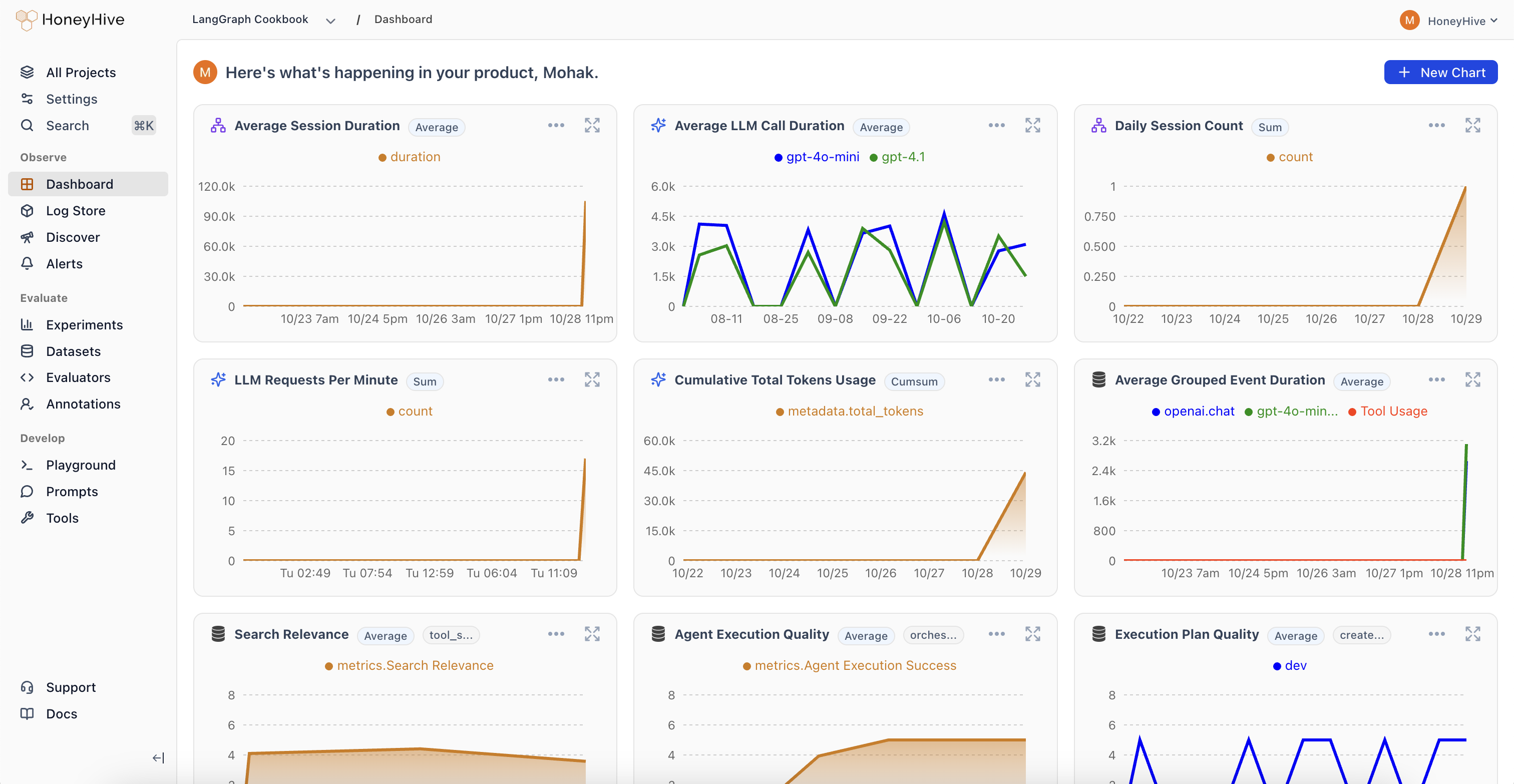
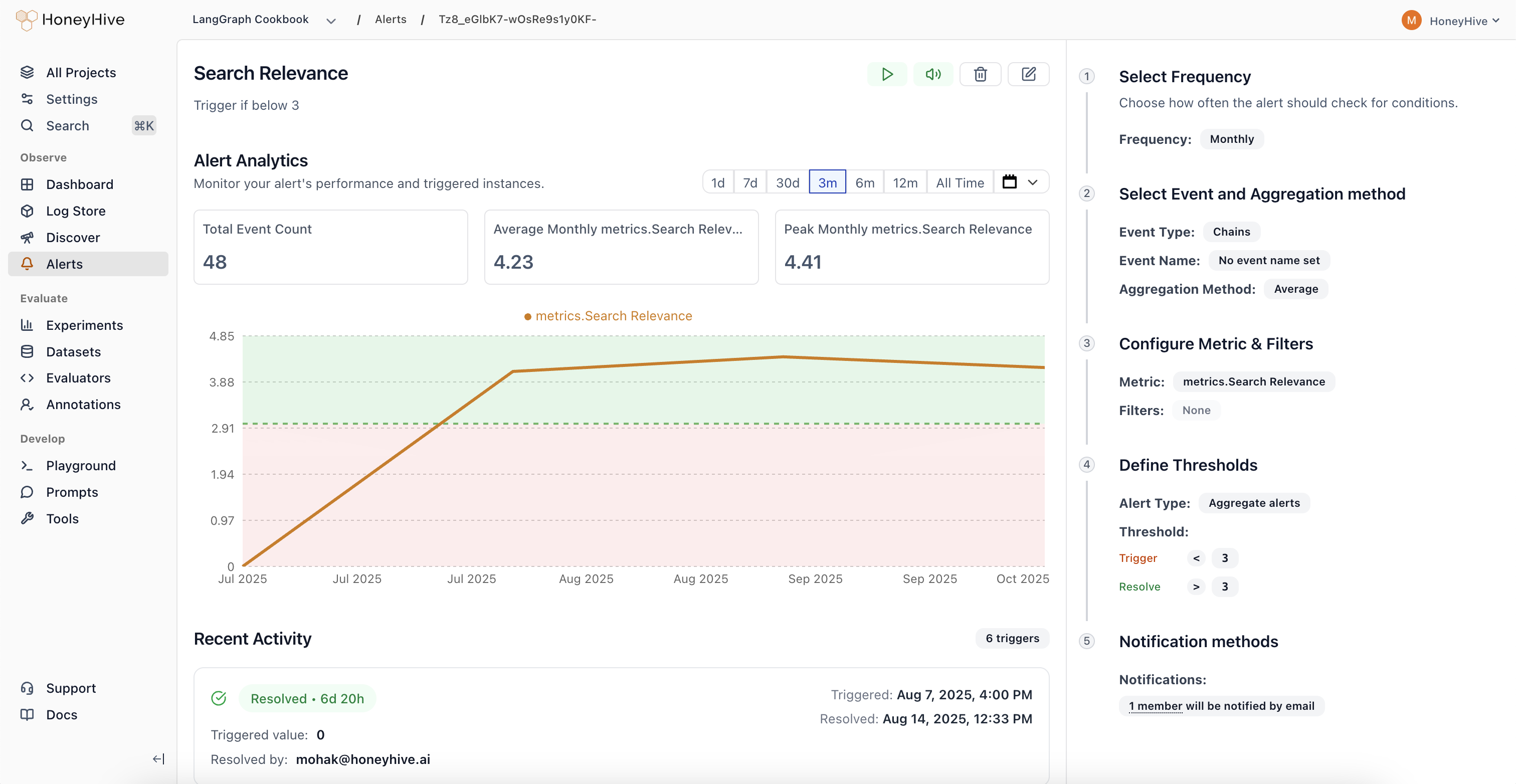
Deploy your AI application with distributed tracing to capture every interaction. Collect real-world traces, user feedback, and quality metrics from production. Run online evals to identify edge cases and evaluate quality at scale. Set up alerts to monitor critical failures or metric drift over time.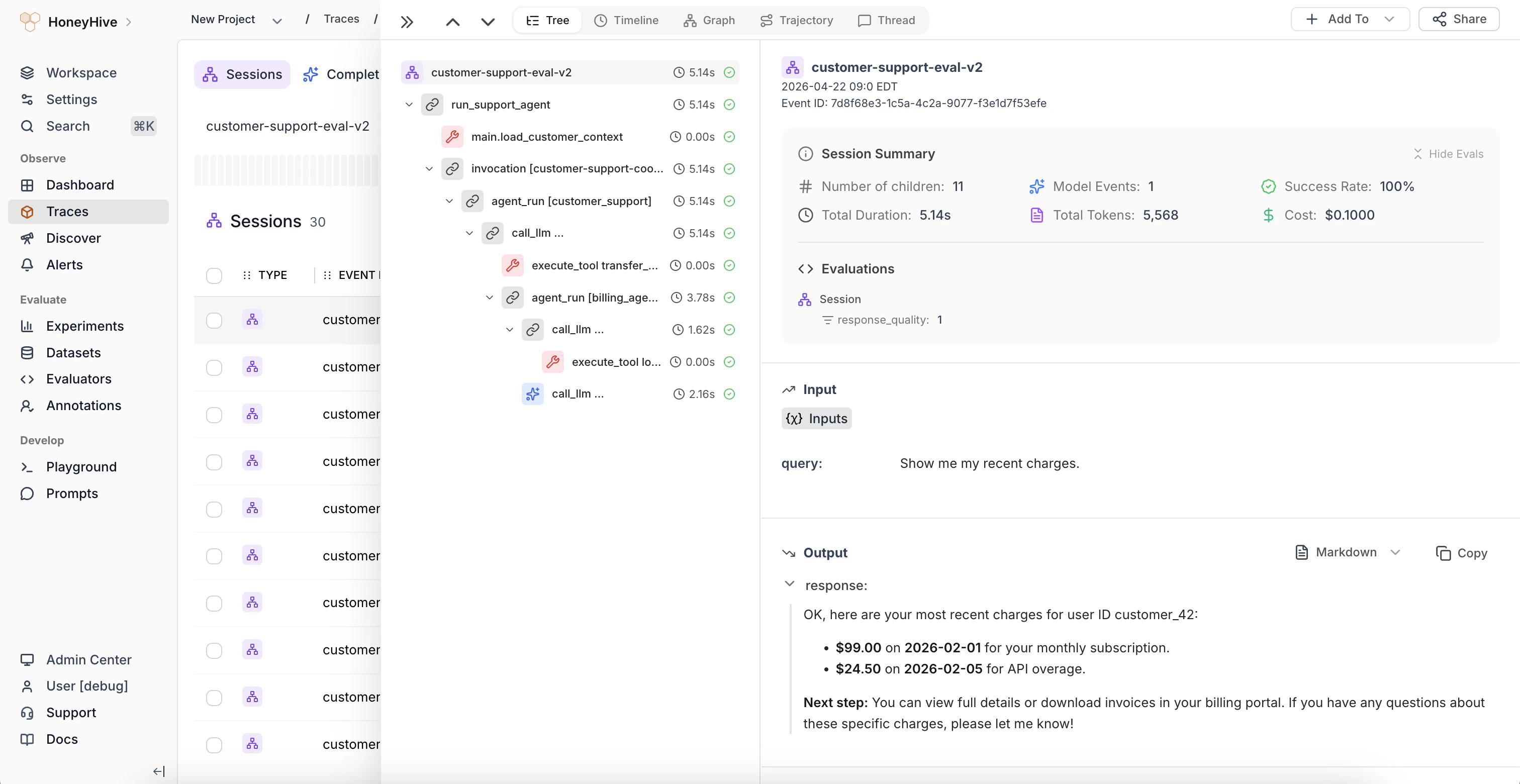
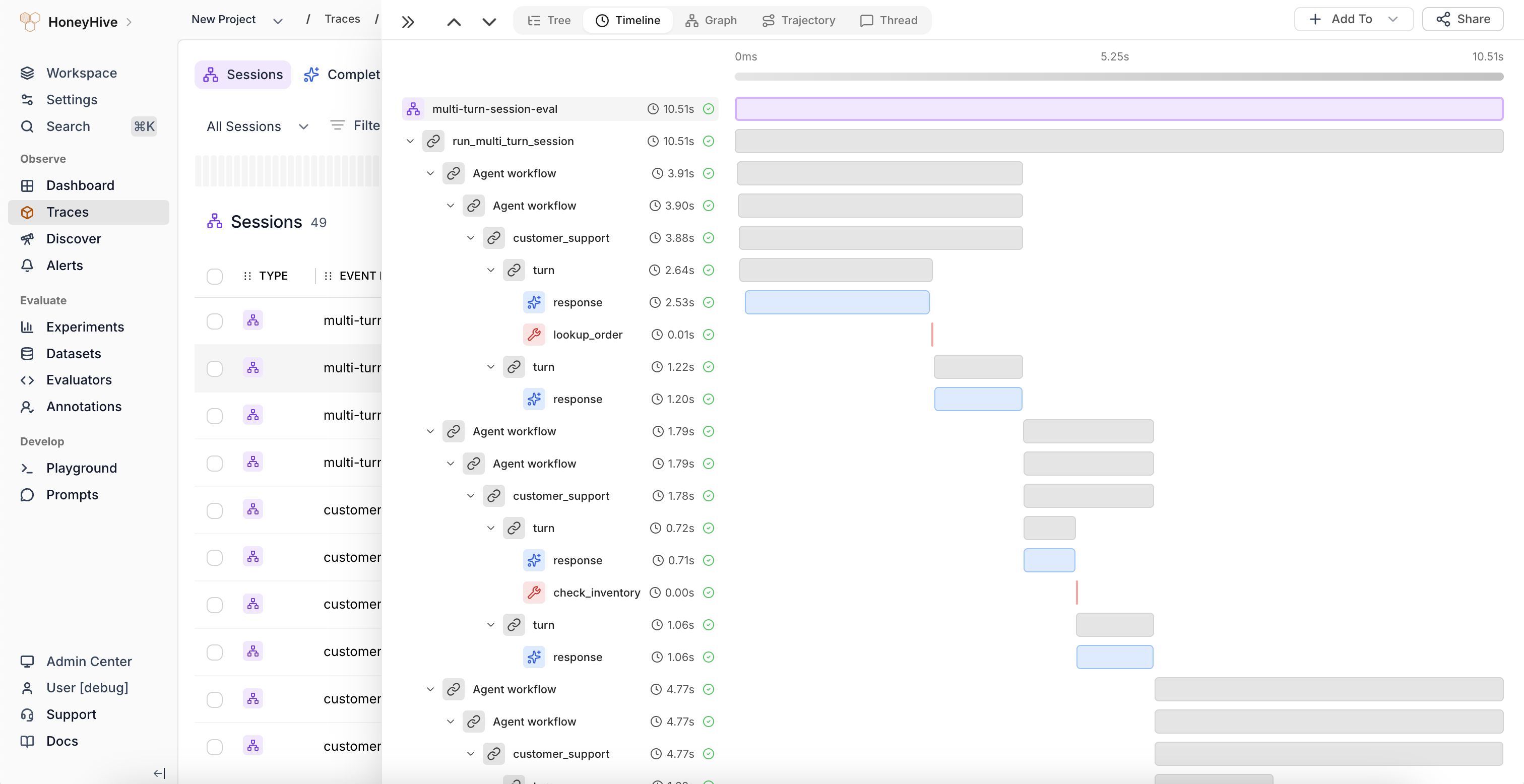
- Traces
- Agent Graphs
- Threads
- Timeline View
- Dashboard
- Alerts
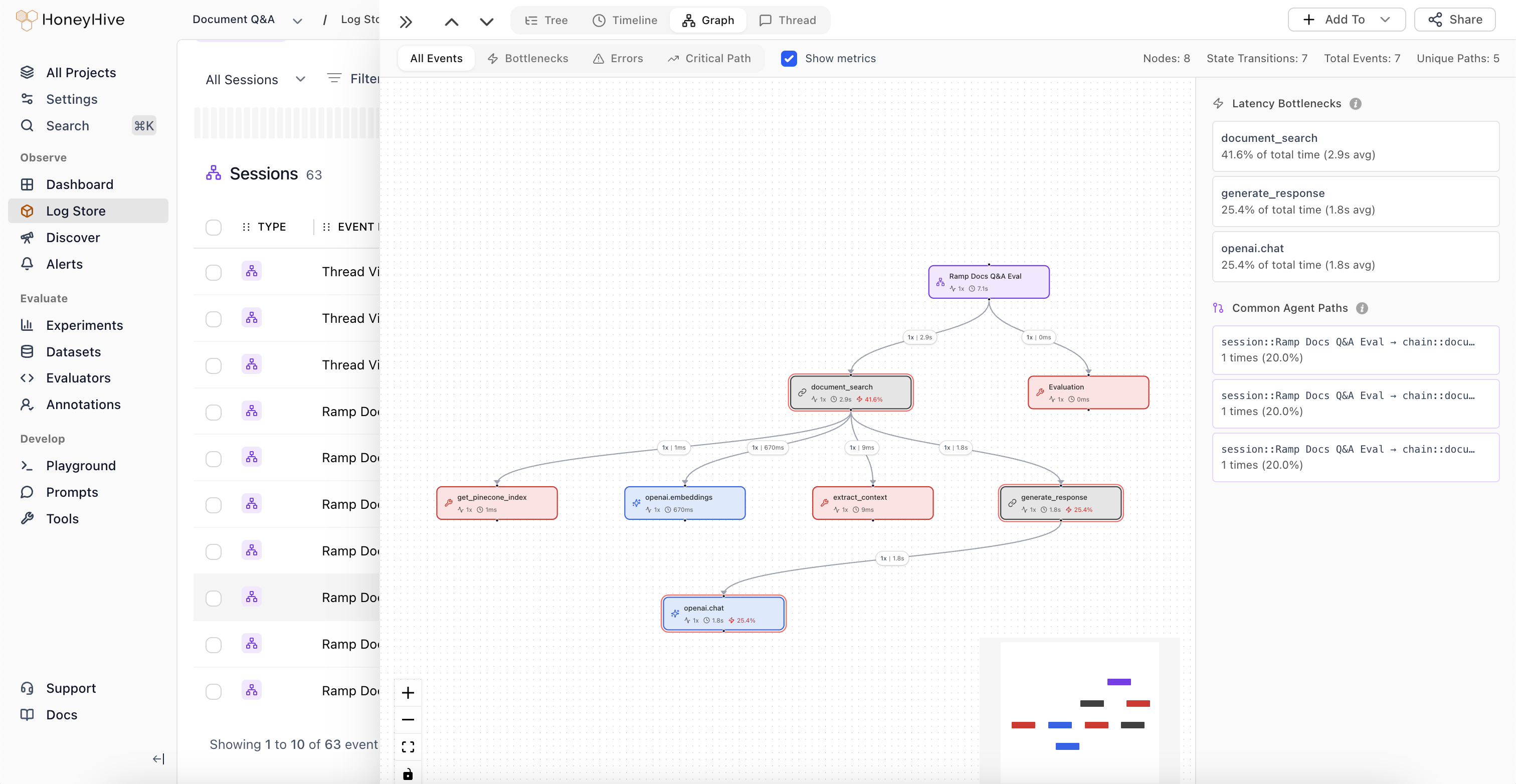
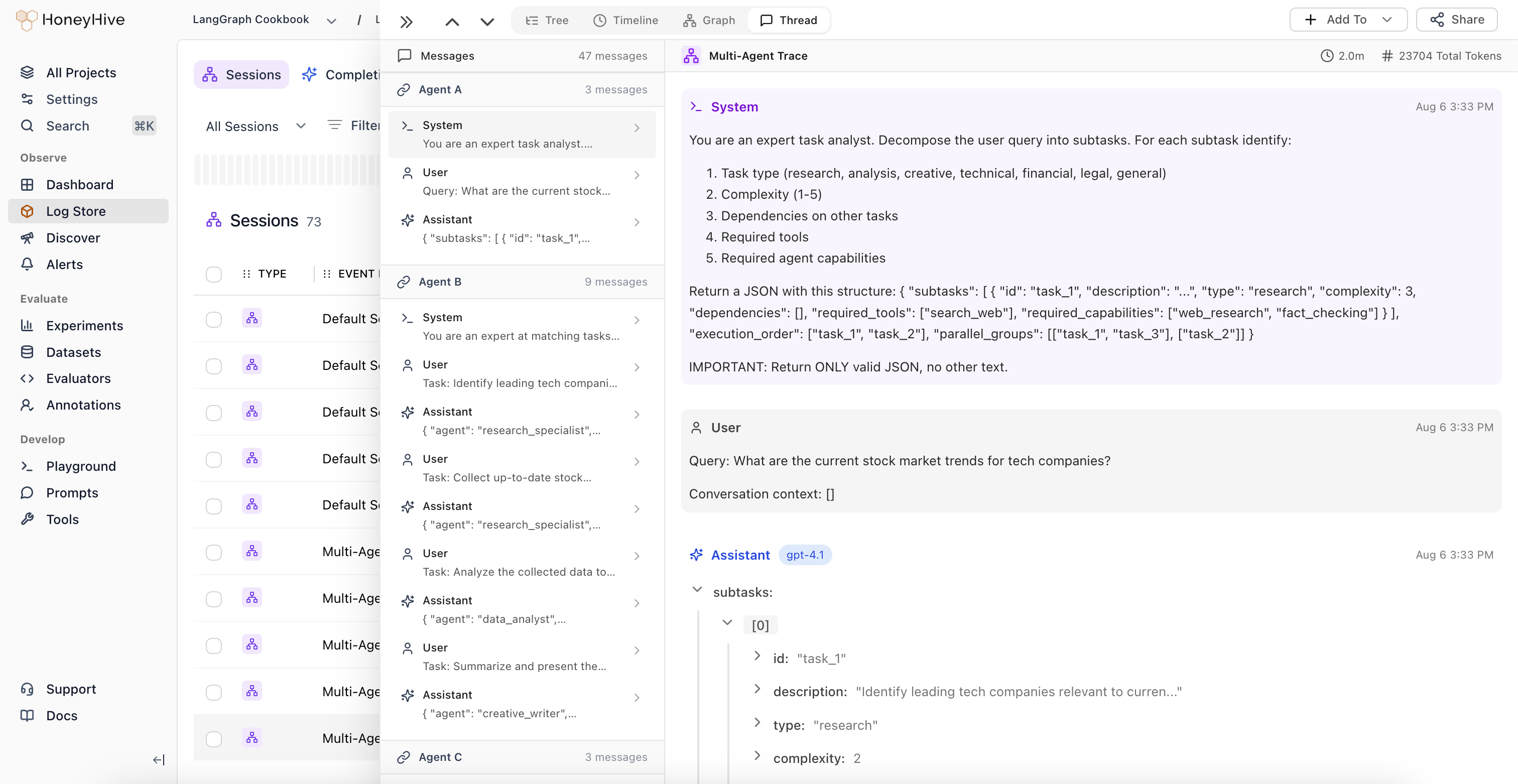
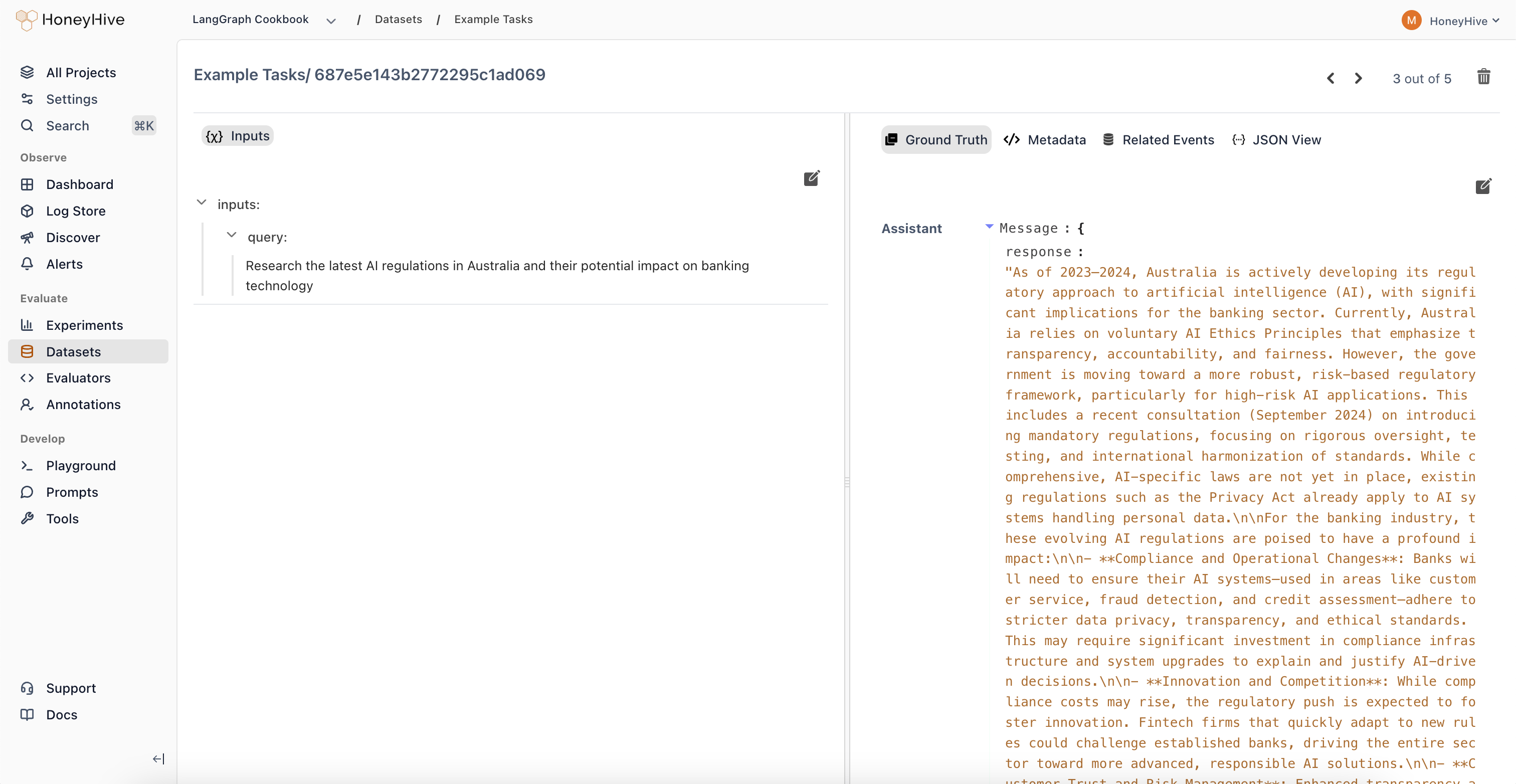
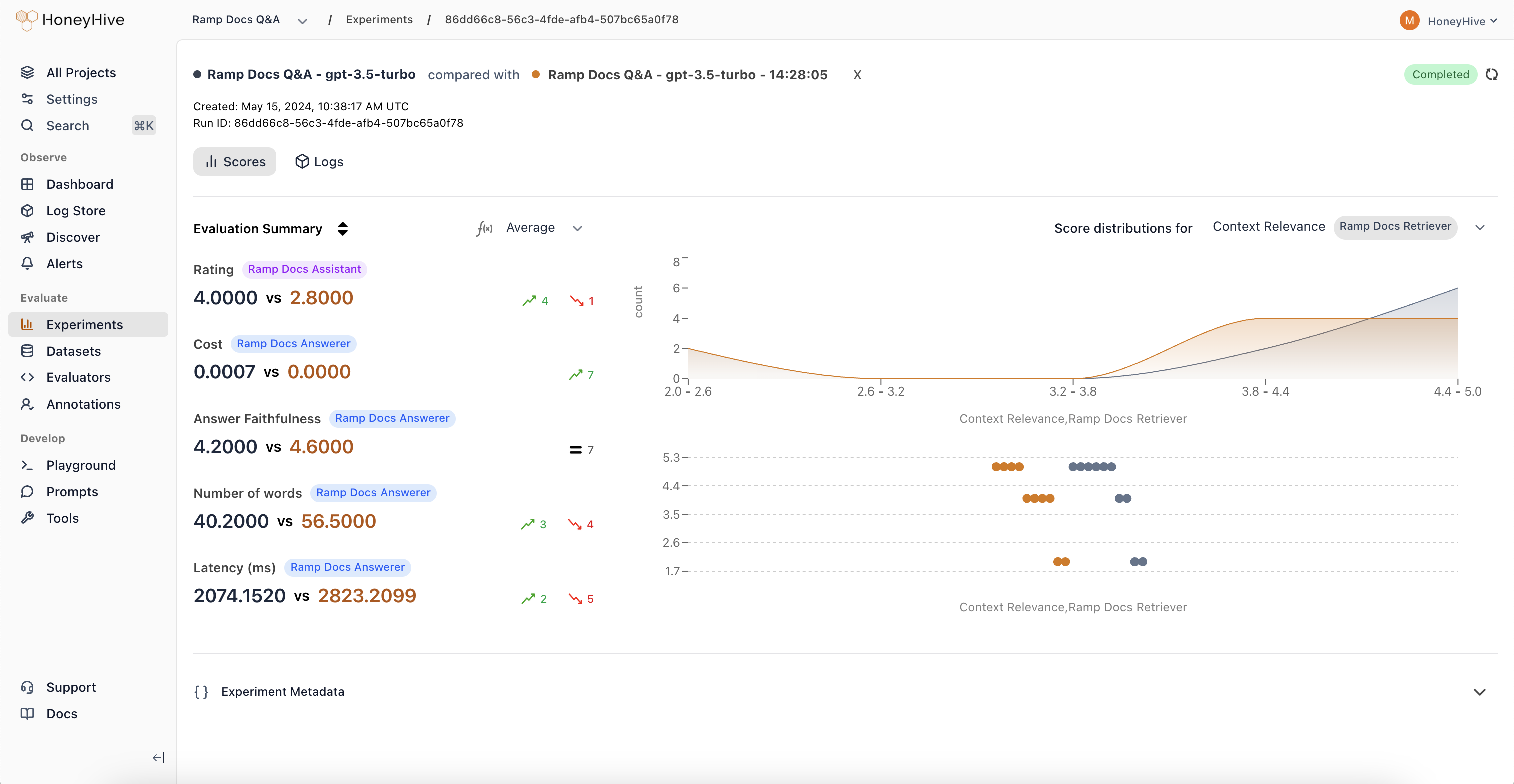
Testing: Curate Datasets & Run Experiments
Transform failing traces from production into curated datasets. Run comprehensive experiments to quantify performance and track regressions as you change prompts, models, tools, and more.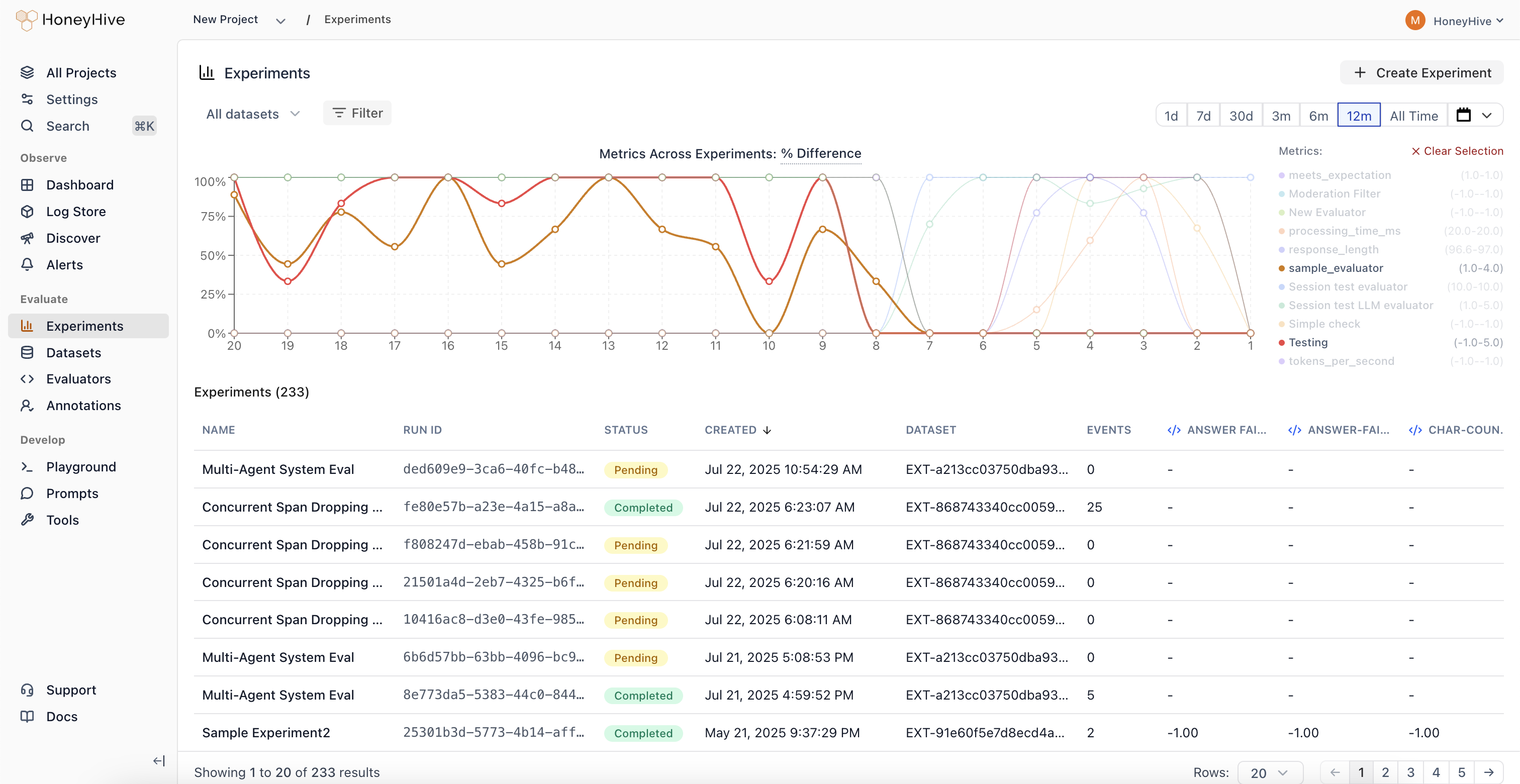
- Experiments
- Datasets
- Regression Tests
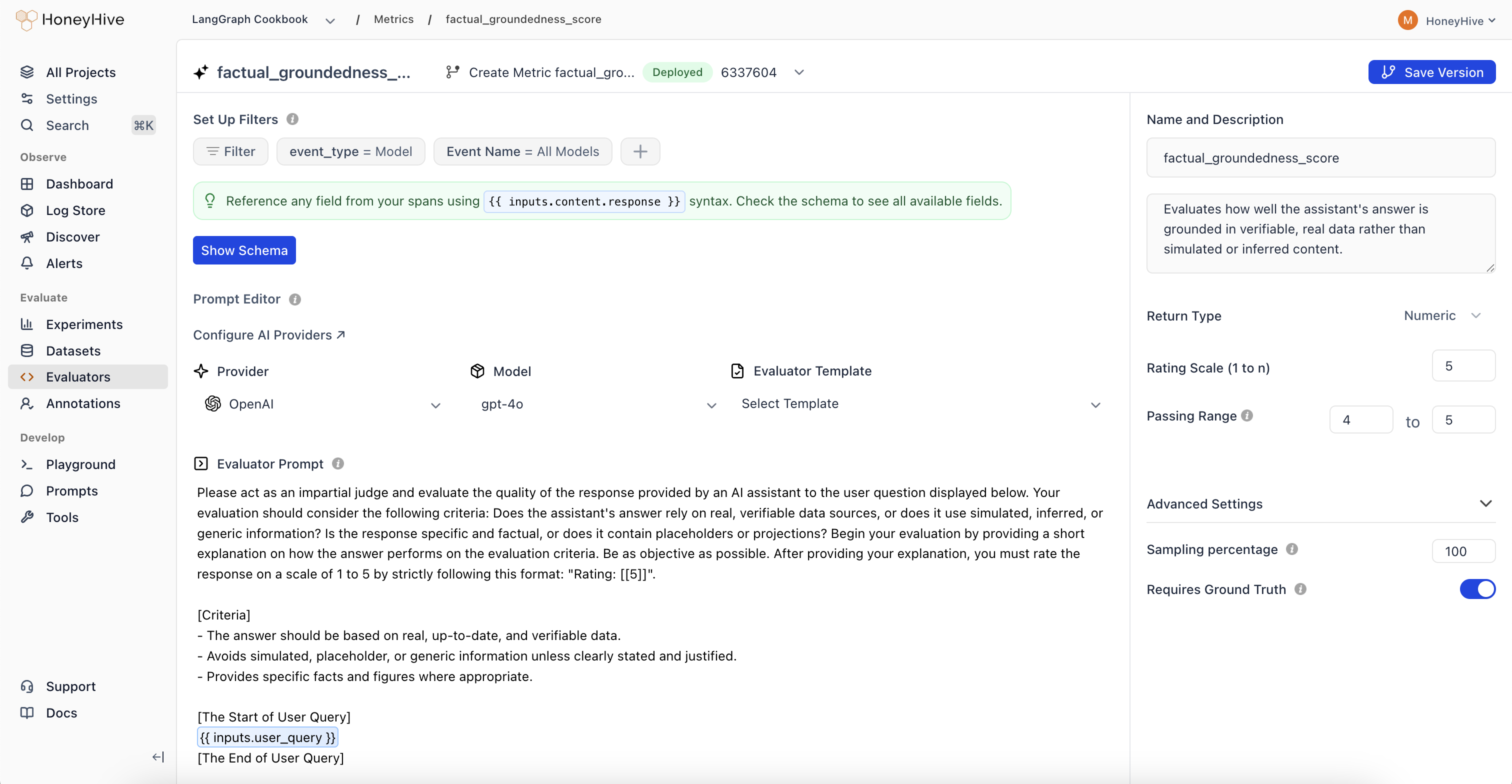
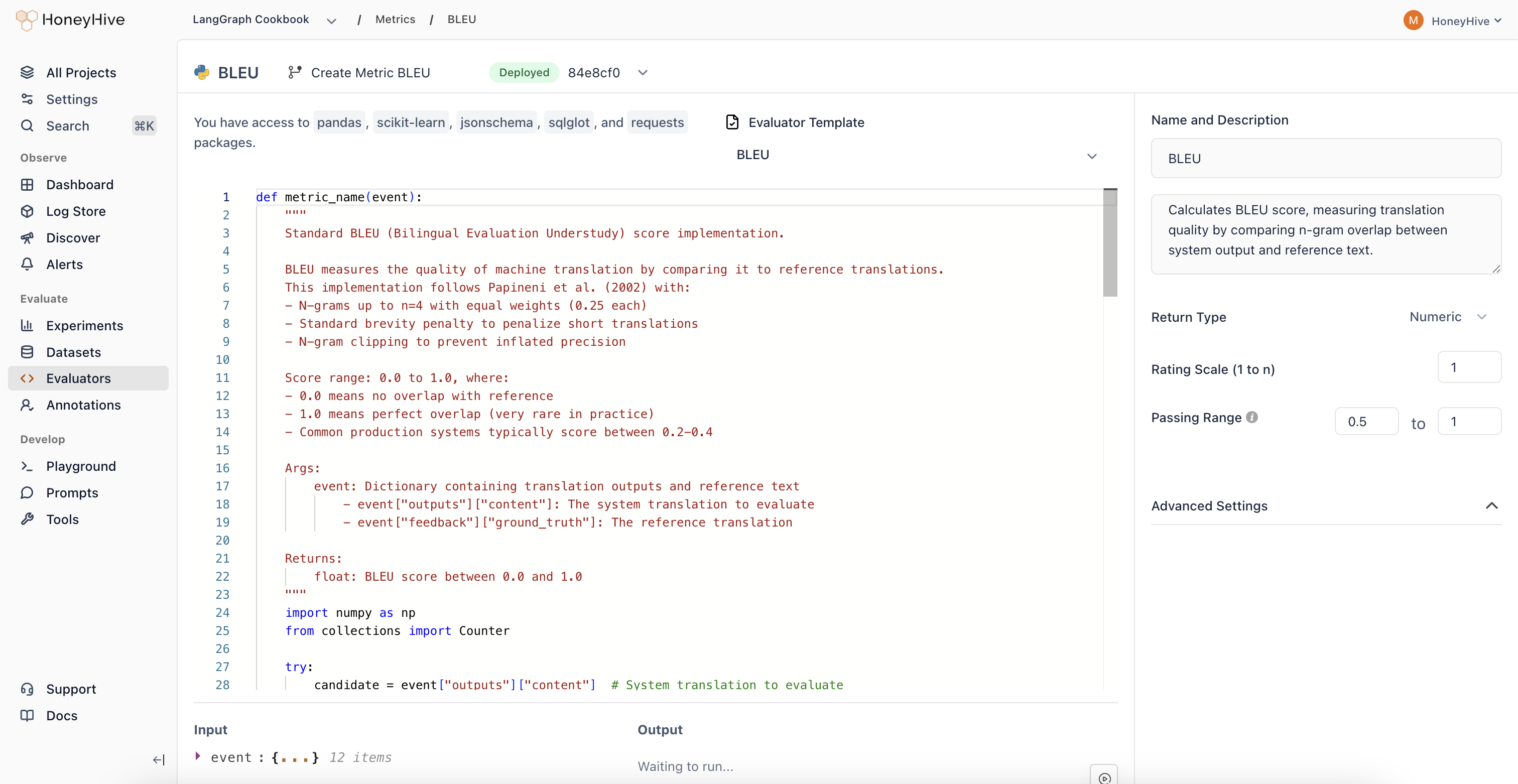
- LLM Evaluators
- Code Evaluators
- Annotation Queues
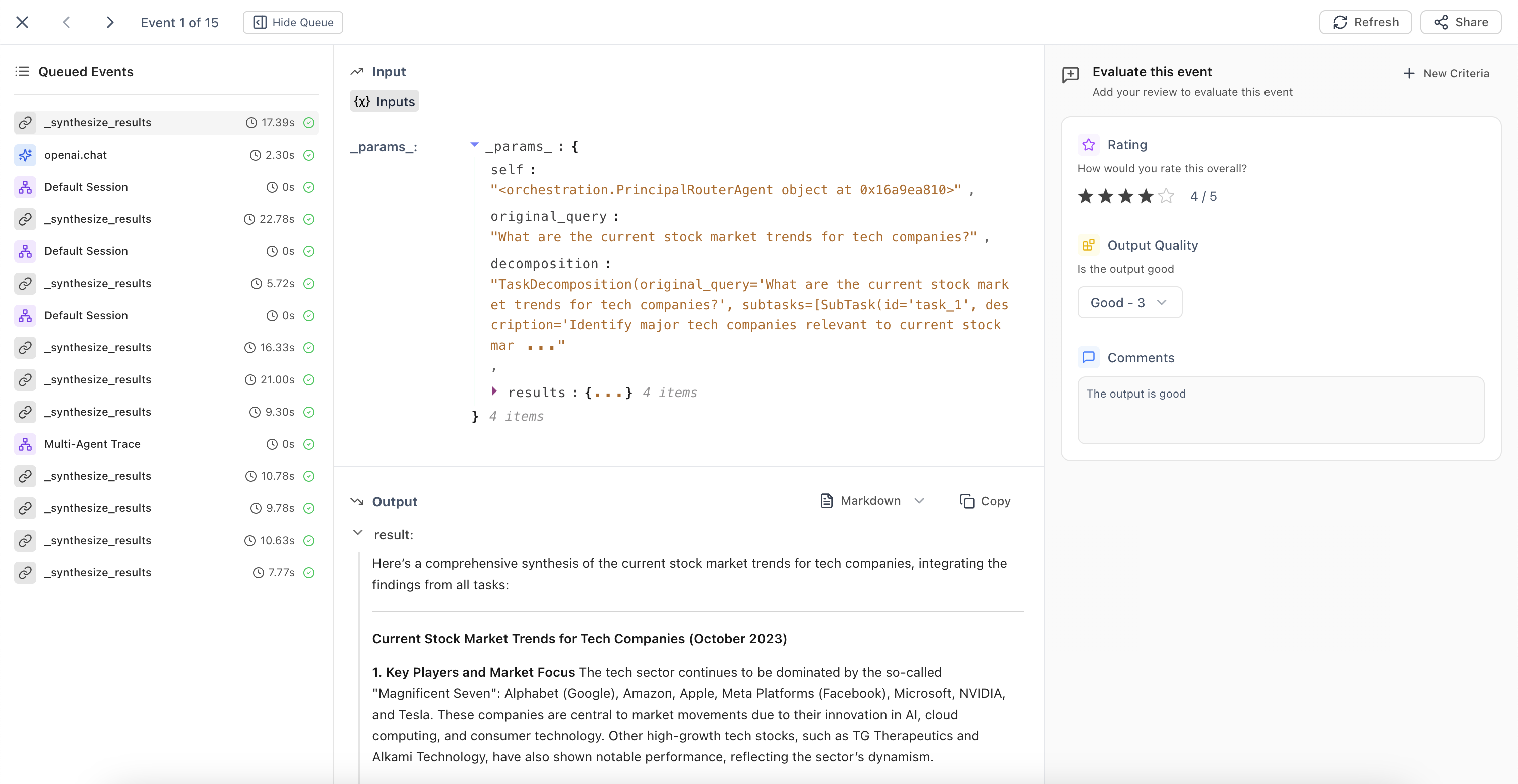
Development: Iterate & Refine Prompts
Use evaluation results to guide improvements. Iterate on prompts, test new models, and optimize your AI application based on data-driven insights. Test changes against your curated datasets before deploying to production.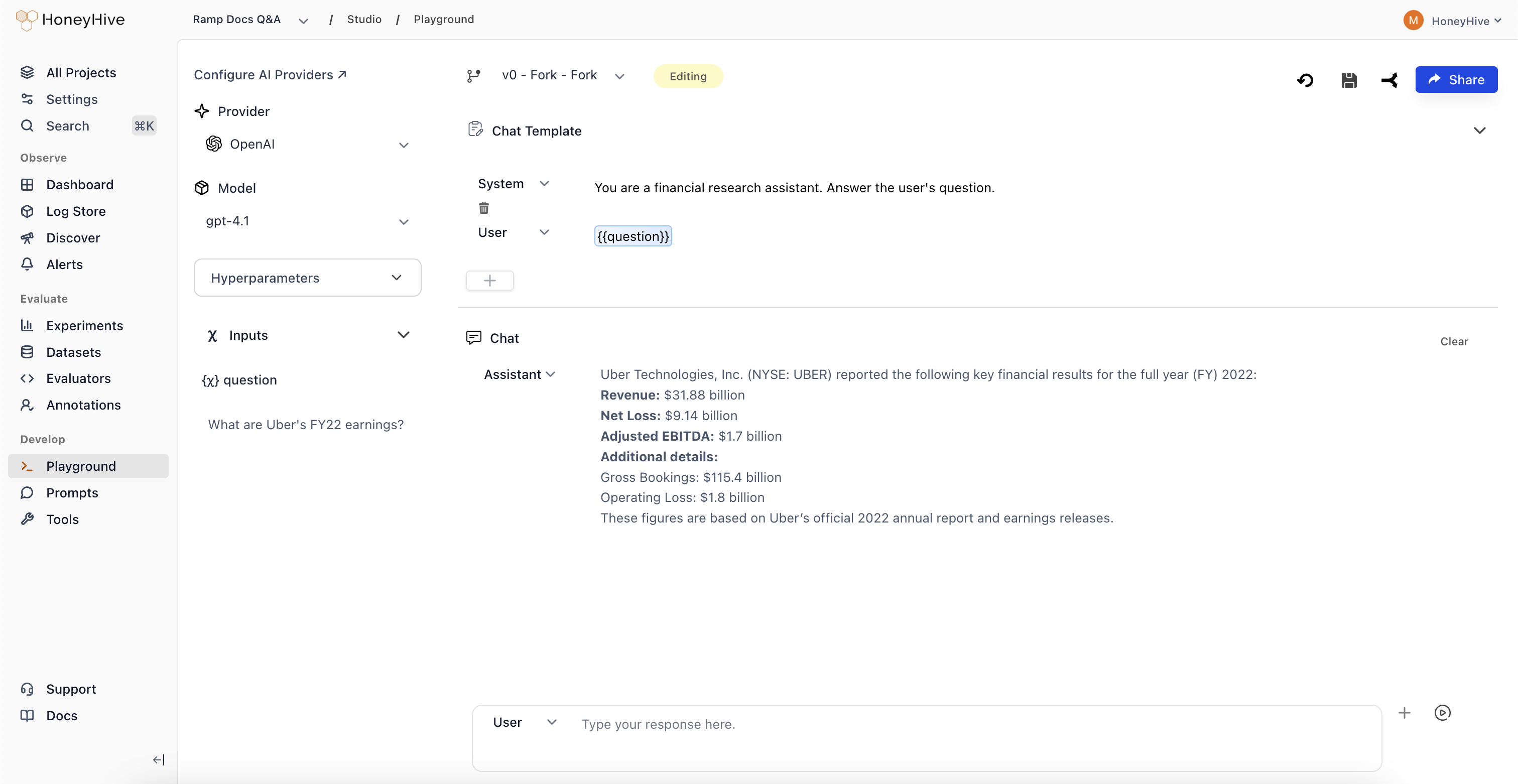
- Playground
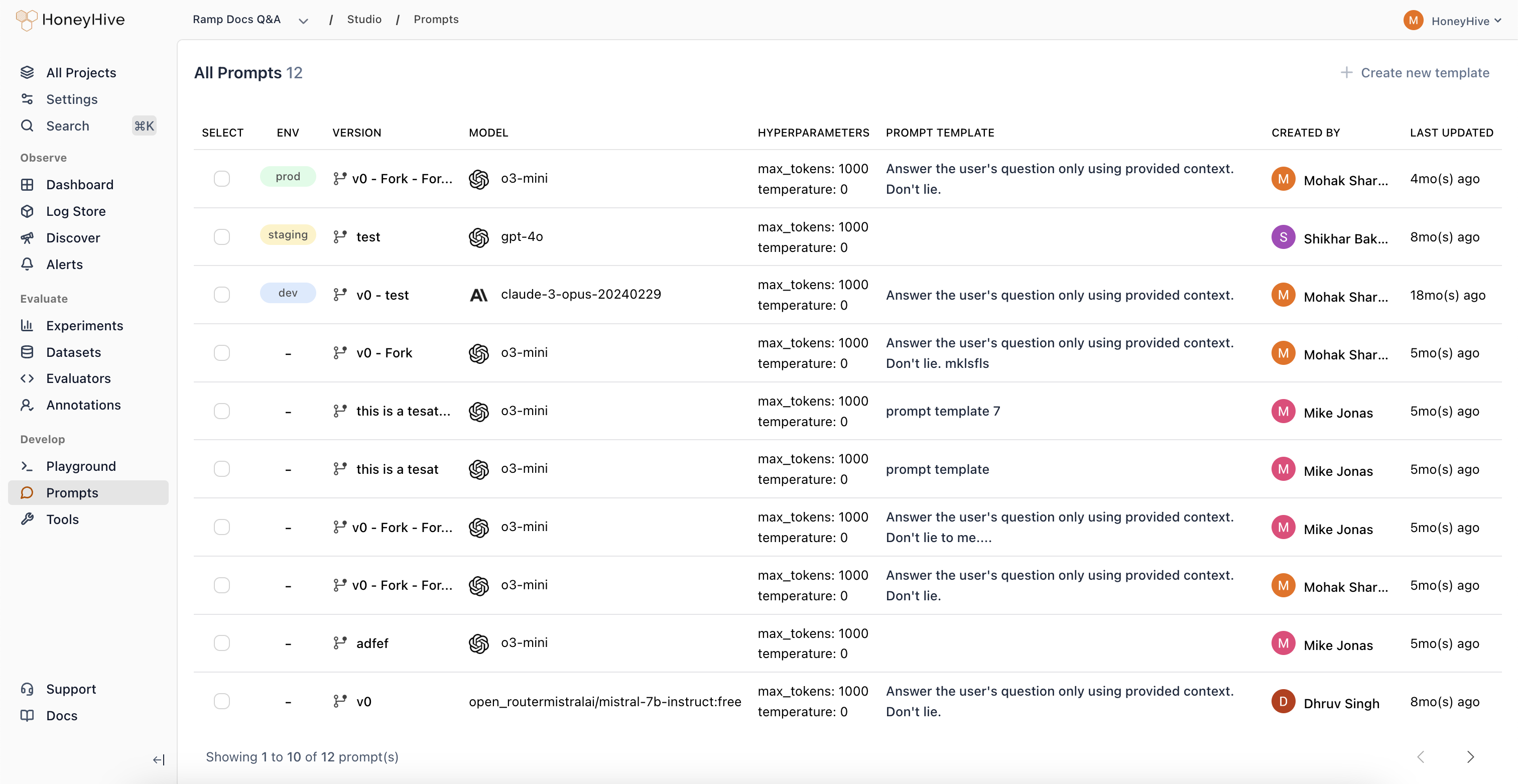
- Prompt Management
.png)
Platform Capabilities
Explore the core features that power your AI development lifecycle:Tracing
Capture and visualize every step of your AI application with distributed tracing.
Experiments & Datasets
Test changes with offline experiments and curated datasets before production.
Monitoring & Alerting
Track metrics with dashboards and get instant alerts when quality degrades.
Online Evaluations
Run automated evals on traces to monitor quality and catch issues early.
Annotation Queues
Collect expert feedback and turn qualitative insights into labeled datasets.
Prompt Management
Centrally manage and version prompts across UI and code.
Open Standards, Open Ecosystem
HoneyHive is natively built on OpenTelemetry, making it fully agnostic across models, frameworks, and clouds. Integrate seamlessly with your existing AI stack with no vendor lock-in.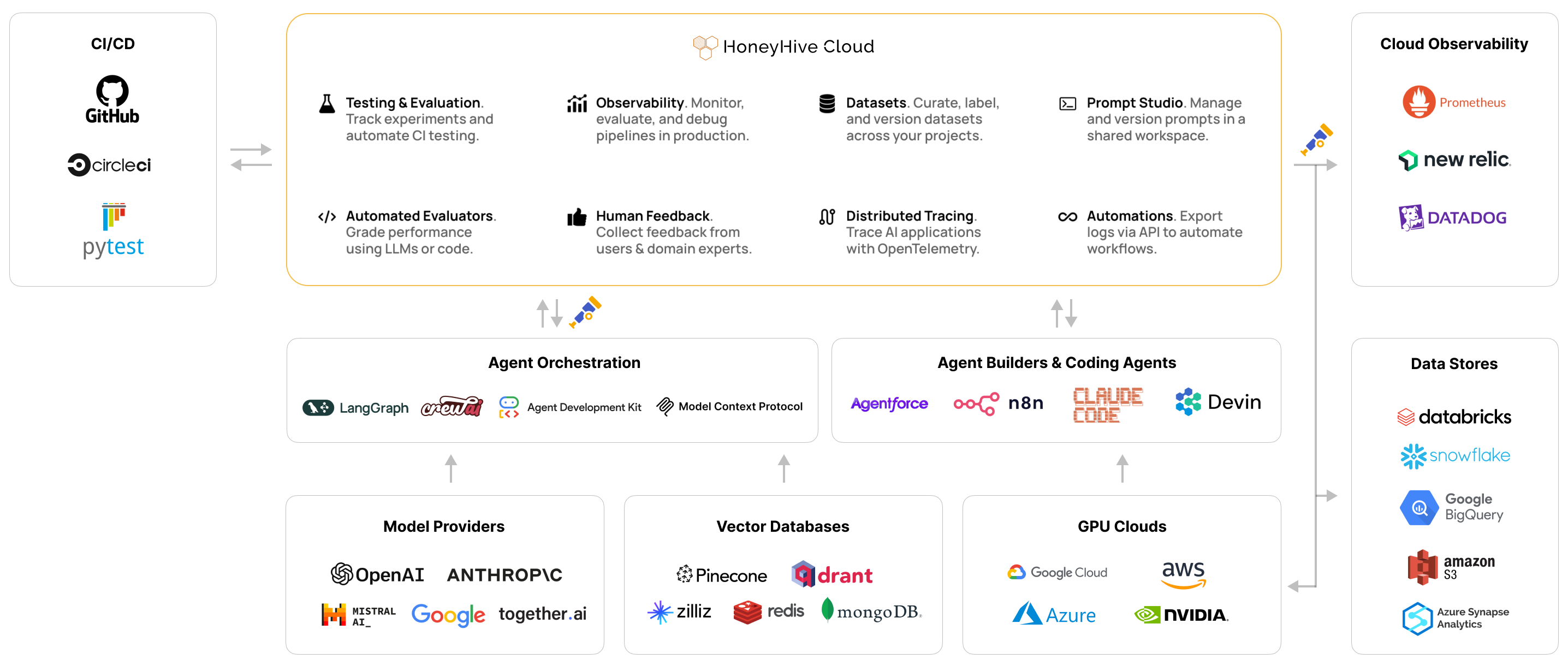
Model Agnostic
Works with any LLM—OpenAI, Anthropic, Bedrock, open-source, and more.
Framework Agnostic
Native support for LangChain, CrewAI, Google ADK, AWS Strands, and more.
Cloud Agnostic
Deploy on AWS, GCP, Azure, or on-premises—works anywhere.
Built on Open Standards
OpenTelemetry-native for interoperability and future-proof infrastructure.
Deployment Options
SaaS Cloud
Fully-managed, multi-tenant platform. Get started in minutes.
Dedicated Cloud
Private, single-tenant environment managed by our team.
Self-Hosted
Deploy in your VPC for complete control and compliance.
Quickstart Guides
Start Tracing
Instrument your first application and capture traces in 5 minutes.
Run Your First Evaluation
Set up experiments and evaluate your AI agents programmatically.
Additional Resources
API Reference
Complete REST API documentation for custom integrations.
SDK Documentation
Python and TypeScript SDK guides for advanced use cases.
Invite Your Team
Add teammates and configure role-based access control.
Integrations
Connect with OpenAI, Anthropic, LangChain, and more.