Looking for the latest HoneyHive docs? See HoneyHive v2.
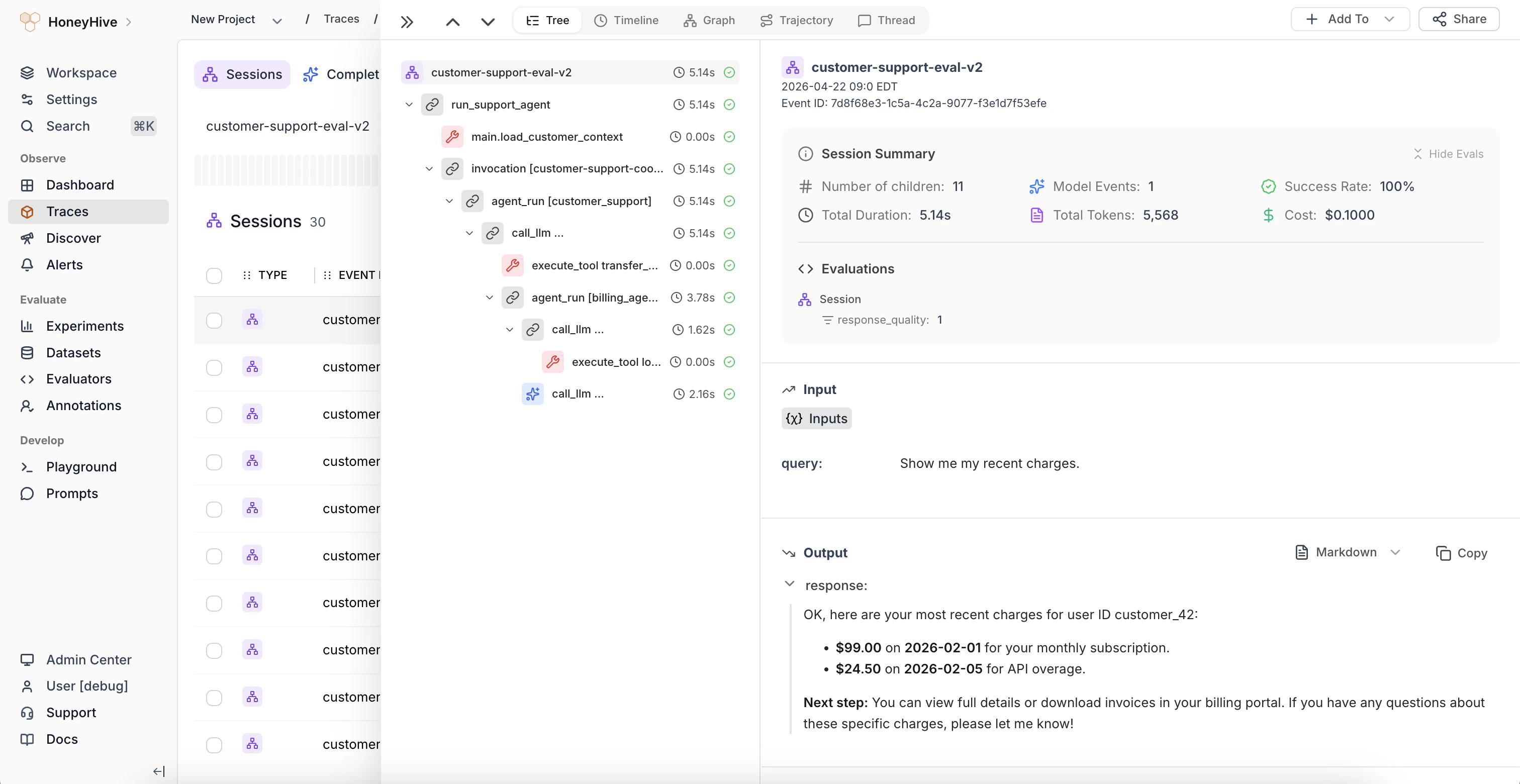
Visualization of a trace in HoneyHive
- Log Execution Data: Log detailed information throughout your AI pipeline.
- Analyze System Behavior: Gain insights into component interactions, including LLM calls and database queries.
- Debug Complex Scenarios: Trace issues across service boundaries in multi-modal AI systems.
- Evaluate Performance: Assess model outputs, prompt effectiveness, and overall system performance.
- Monitor Key Metrics: Track latency, token usage, costs, and custom KPIs in real-time.
Understanding Sessions and Events
HoneyHive’s tracing system represents your code’s execution flow across different processes and services as a hierarchical tree of events. This structure provides a comprehensive view of your application’s execution flow: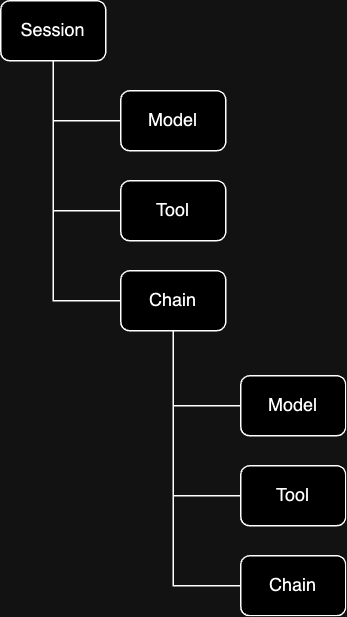
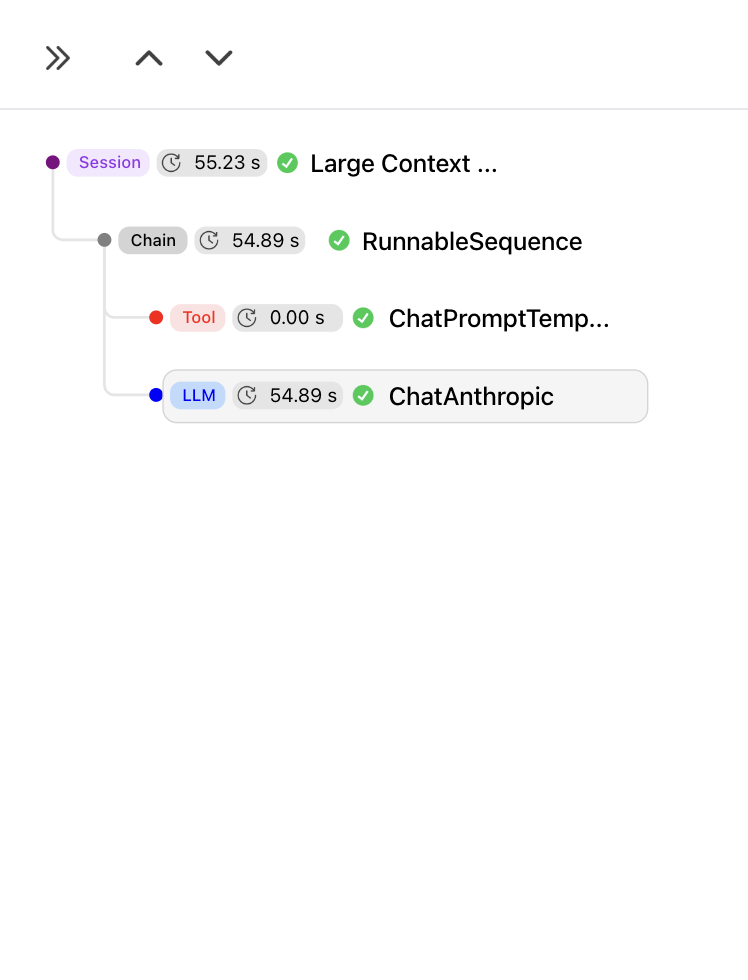
Visualization of a trace in HoneyHive: Tree structure (left) and detailed view (right)
Session
The root event in the tree is called asession event, which is equivalent to trace in Application Performance Monitoring (APM) tools. A session represents a complete interaction or process within your AI application, grouping together all subsequent events in that trace.
Events
Eachsession is composed of nested events, which are equivalent to spans in APM tools. Events represent discrete operations or steps in your application’s execution. They can be of different types:
ModelEvents:- Represent API requests to any model providers
- Capture input prompts, output responses, and relevant metadata
- Example: A GPT-4o completion request or a DALL-E image generation call
ToolEvents:- Represent API requests to external services or tools
- Can include API calls, database queries, or custom function executions
- Example: A vector database similarity search, an external API call for internet search, etc.
ChainEvents:- Contain nested events
- Represent a sequence of operations or a logical grouping of related actions
- Example: A multi-step reasoning process or a complex query pipeline
Getting Started
Automatic Tracing
For those looking to get started quickly, we recommend our automatic tracing method. This method automatically instruments major LLM providers and even vector database requests with minimal setup using OpenTelemetry’s Semantic Conventions.Quickstart
Begin tracing sessions with HoneyHive in minutes
Supported Integrations
Explore our wide range of pre-built integrations
Tracing Custom Spans
While automatic tracing covers many use cases, you may need to instrument custom logic or code not captured automatically. Custom Spans allow you to trace any function in your codebase.Tracing Custom Spans
Trace any custom spans in Python/TS using function decorators.
Enriching Traces
To maximize the value of your traces, you can enrich any event with additional properties such asuser feedback, user properties, evaluations, configs, metadata, and more.
Enriching Traces
Learn how to add valuable context to your traces
Advanced Tracing Techniques
For mature AI teams with complex requirements, we offer advanced tracing capabilities:Distributed Tracing
Track execution across multiple services
Multi-Modal Tracing
Instrument multi-modal AI pipelines effectively
Multi-Threaded Tracing (Python)
Trace multi-threaded Python applications
Online Experimentation & A/B Testing
Conduct A/B tests on metrics and feedback
Manual Instrumentation via API
For scenarios requiring fine-grained control over tracing or when using languages outside of Python and JS/TS, we offer manual instrumentation options:Tracing via API
Implement custom tracing logic via our APIs
API Reference
Explore our comprehensive API documentation
Next Steps
Now that you’re familiar with HoneyHive’s tracing capabilities, we recommend:- Setting up automatic tracing in a test environment using our Quickstart Guide
- Experimenting with custom spans in your code
- Exploring our advanced features to optimize your AI workflows