Project
Everything in HoneyHive is organized by projects. A project is a logically-separated workspace to develop, evaluate, and monitor a specific AI agent or an end-to-end application leveraging one or multiple agents.Observability
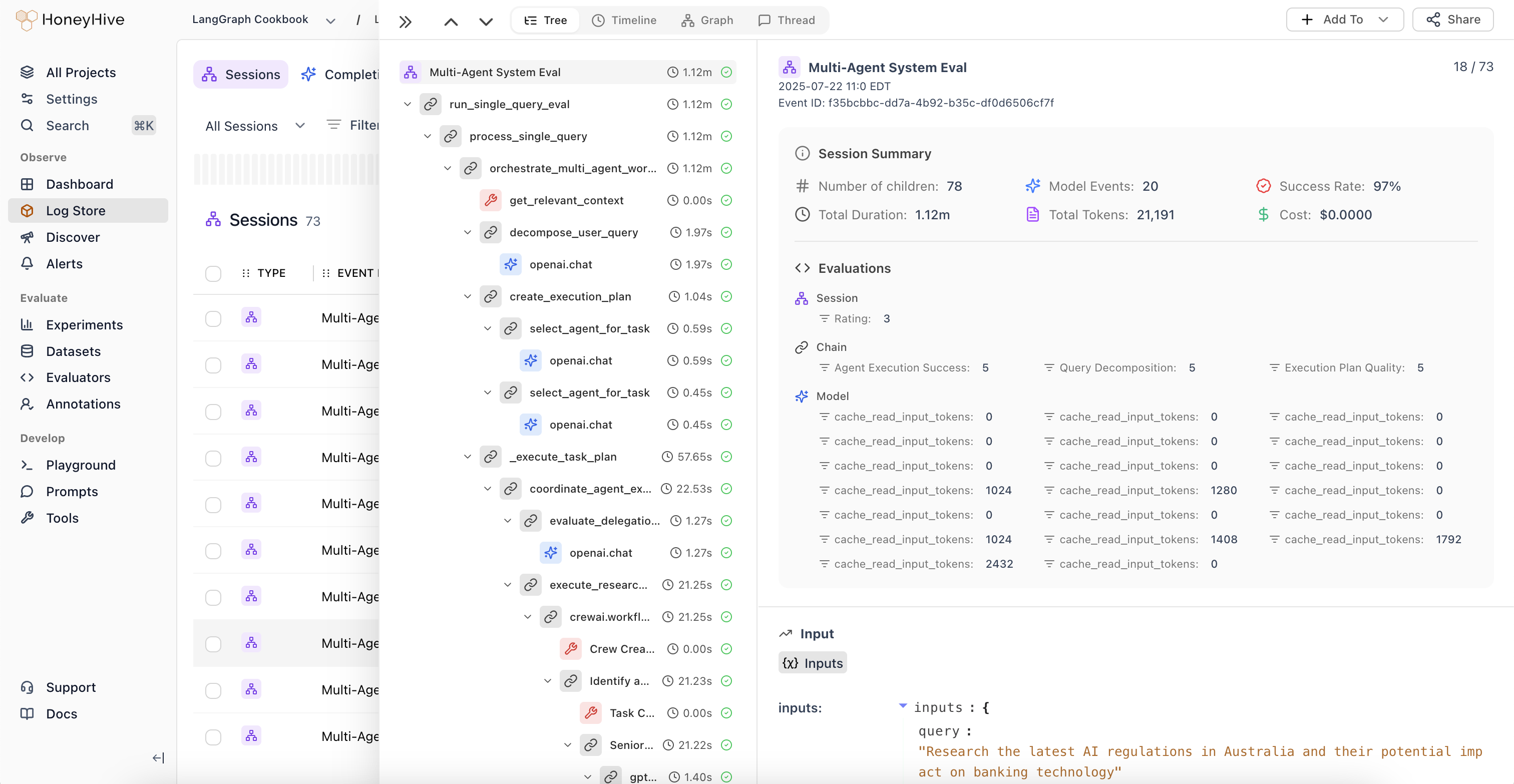
Session
Asession is a collection of events that represent a single user interaction with your application. Sessions can trace a single agent execution or an end-to-end user conversation with multiple turns, depending on your configuration.
Event
Anevent tracks the execution of a specific operation in your application, along with inputs, outputs, metadata, and feedback. This is synonymous with a single span in a trace.
Events have three types:
| Type | Use Case |
|---|---|
model | LLM API calls (OpenAI, Anthropic, etc.) |
tool | External calls (vector DBs, APIs, functions) |
chain | Logical groupings of multiple events |
Tracing Introduction
Data model, OpenTelemetry architecture, and context propagation.
Evaluation
Datapoint
A datapoint is an input-output pair (with optional ground truth and metadata) that represents a single test case. Datapoints can be created manually or saved directly from production traces.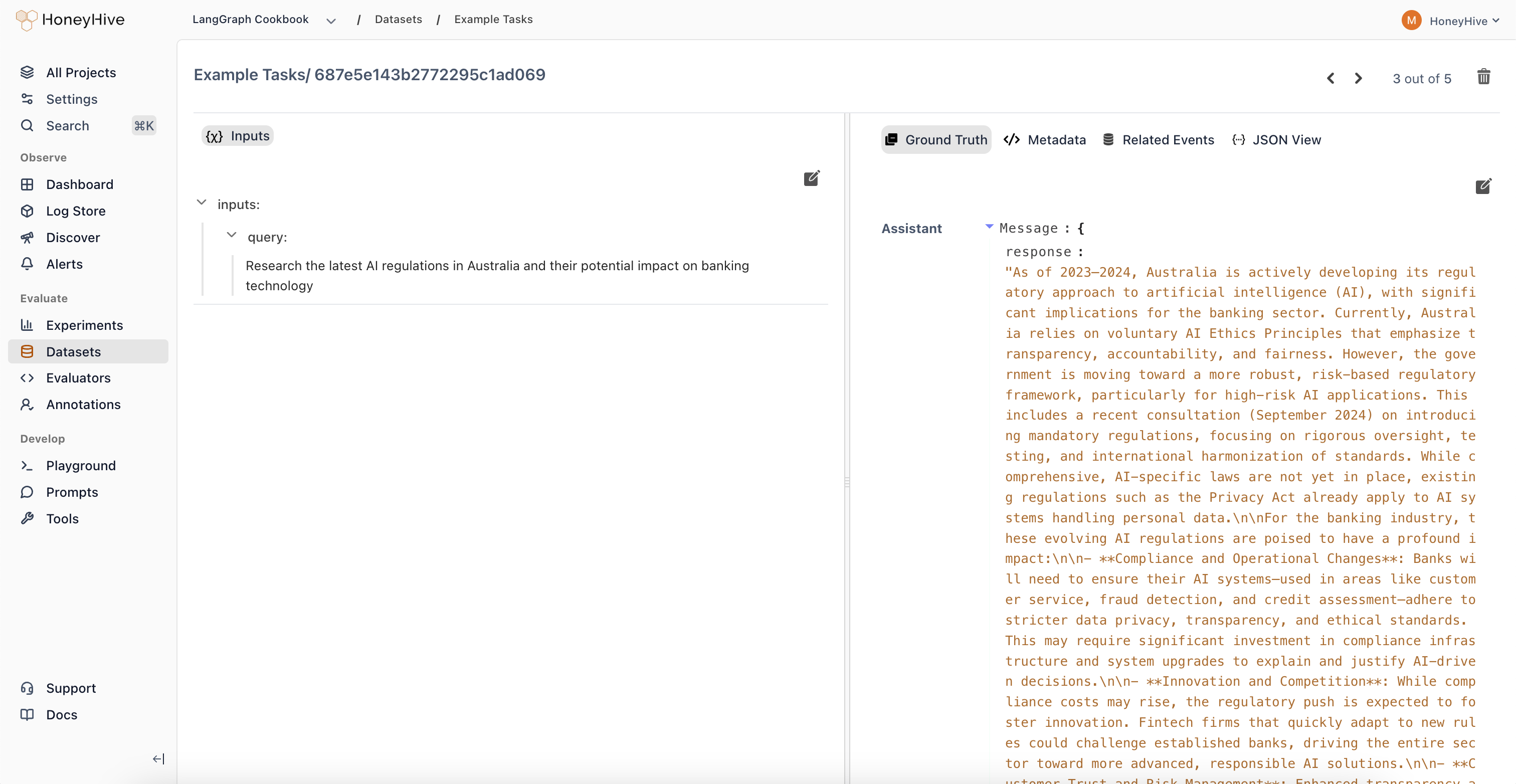
datapoint_id used to track it across experiments and comparisons. Datapoints link back to the events that generated them.
Dataset
A dataset is a collection of datapoints used to run evaluations, compare model versions, or fine-tune custom models. Datasets can be exported and used programmatically in your CI pipelines. Learn more in Datasets.Experiment Run
An experiment run executes your application against a dataset and scores the outputs with evaluators. Experiments track metrics across all datapoints, enabling you to compare different versions of your application.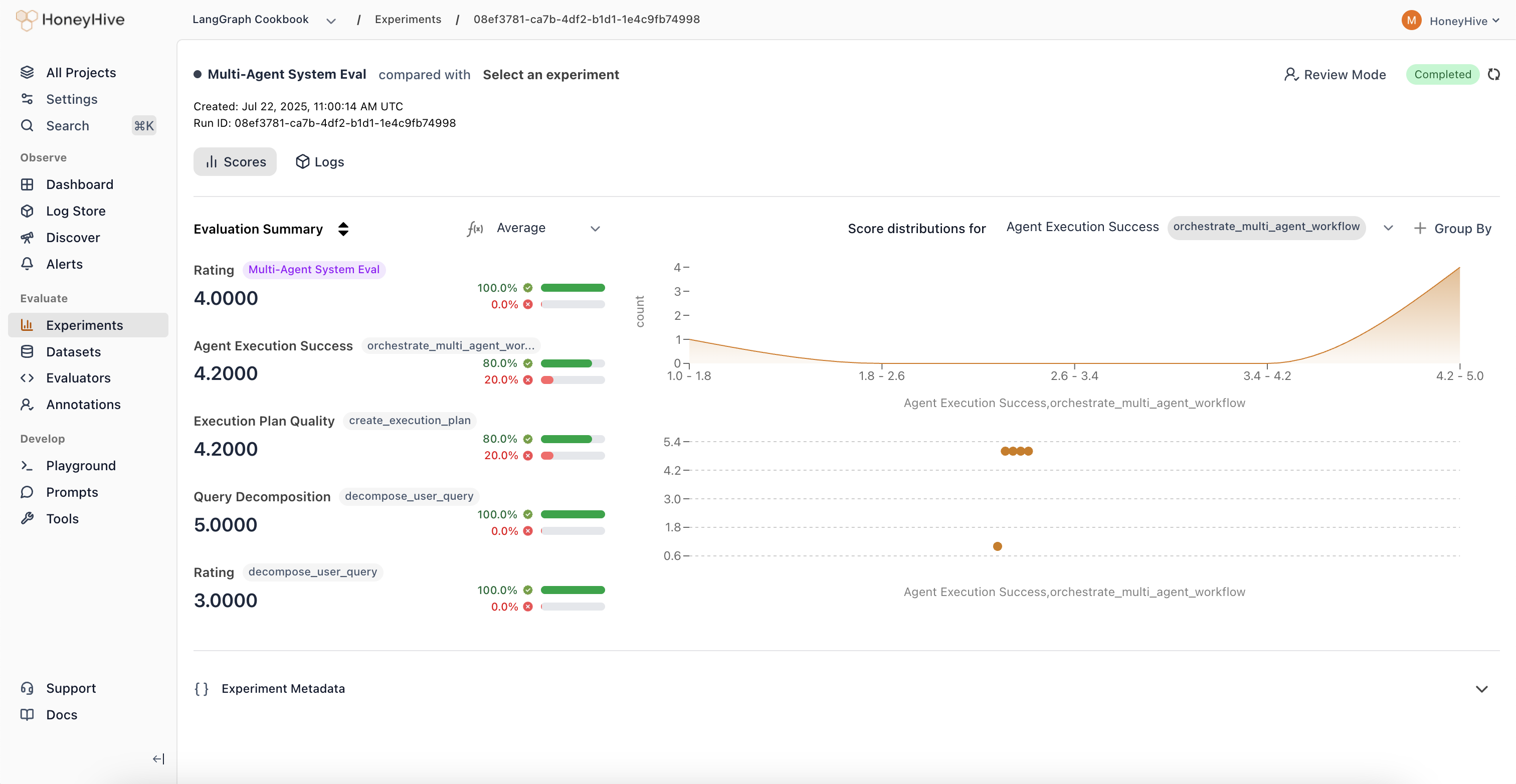
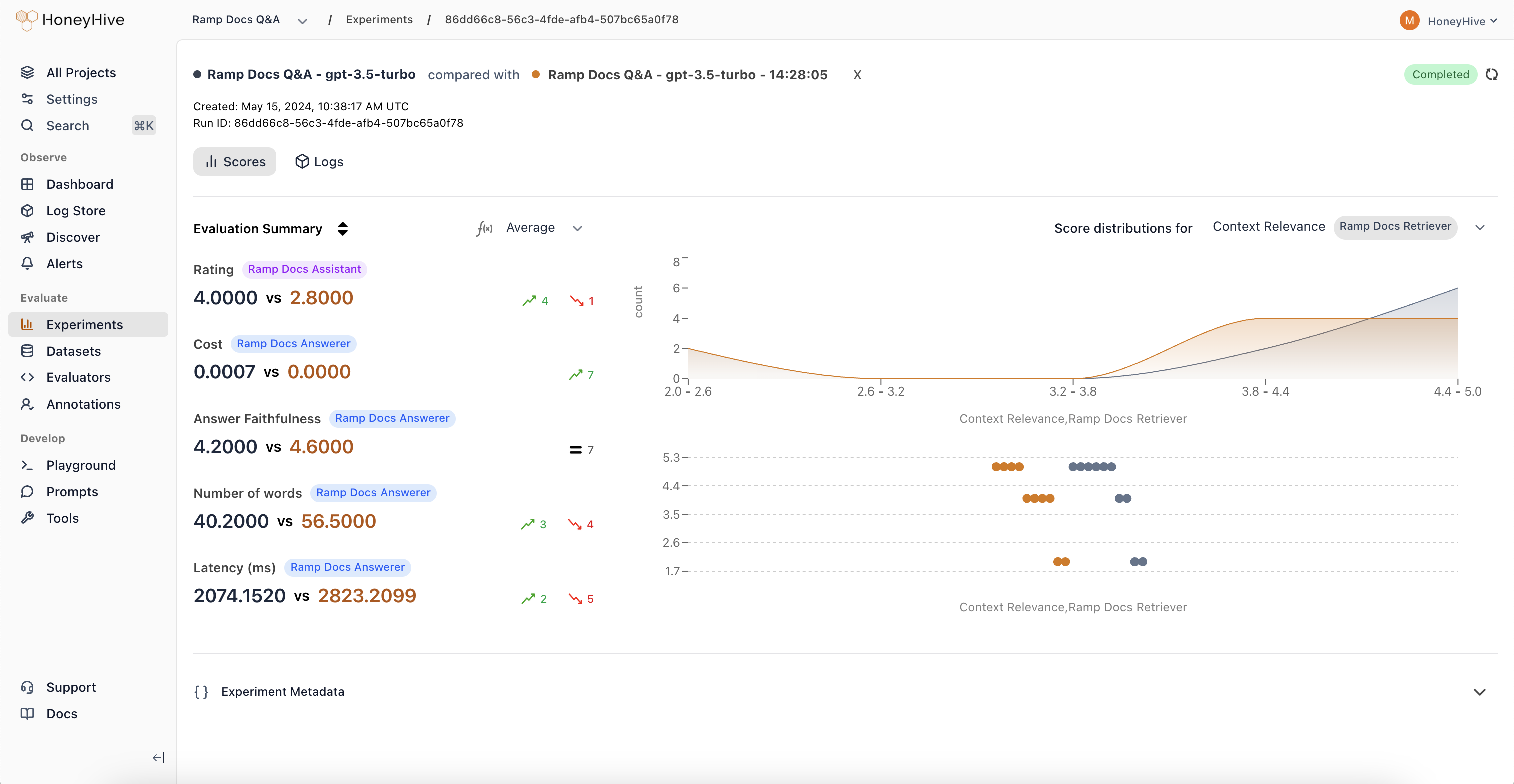
datapoint_id in metadata.
Evaluator
An evaluator is a function that scores your application’s outputs. Evaluators can be:- Python functions - Custom logic you define
- LLM-as-judge - Use an LLM to assess quality
- Human evaluation - Route to annotation queues
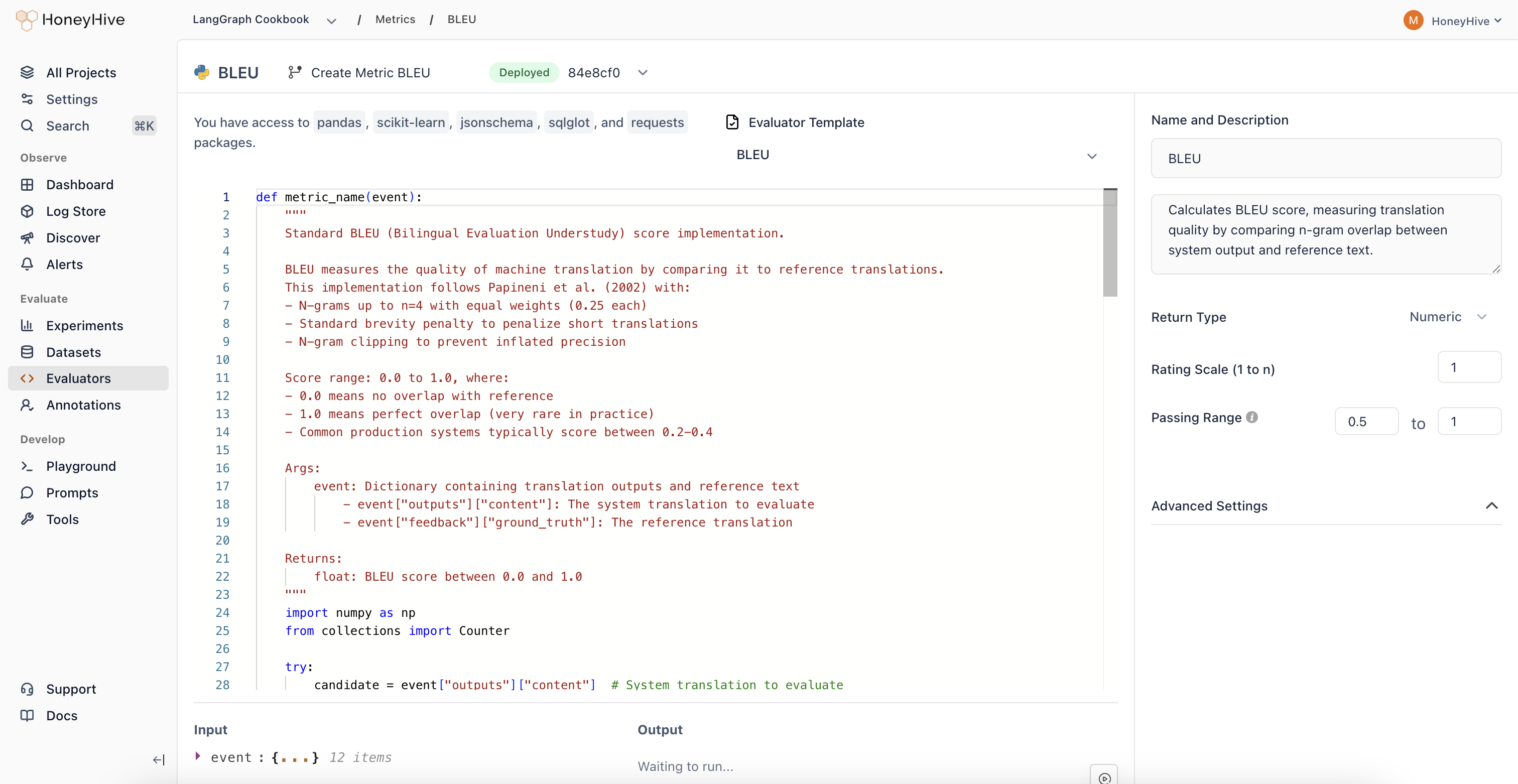
Evaluation Framework
Understand the evaluation philosophy and how datasets, experiments, and evaluators work together.
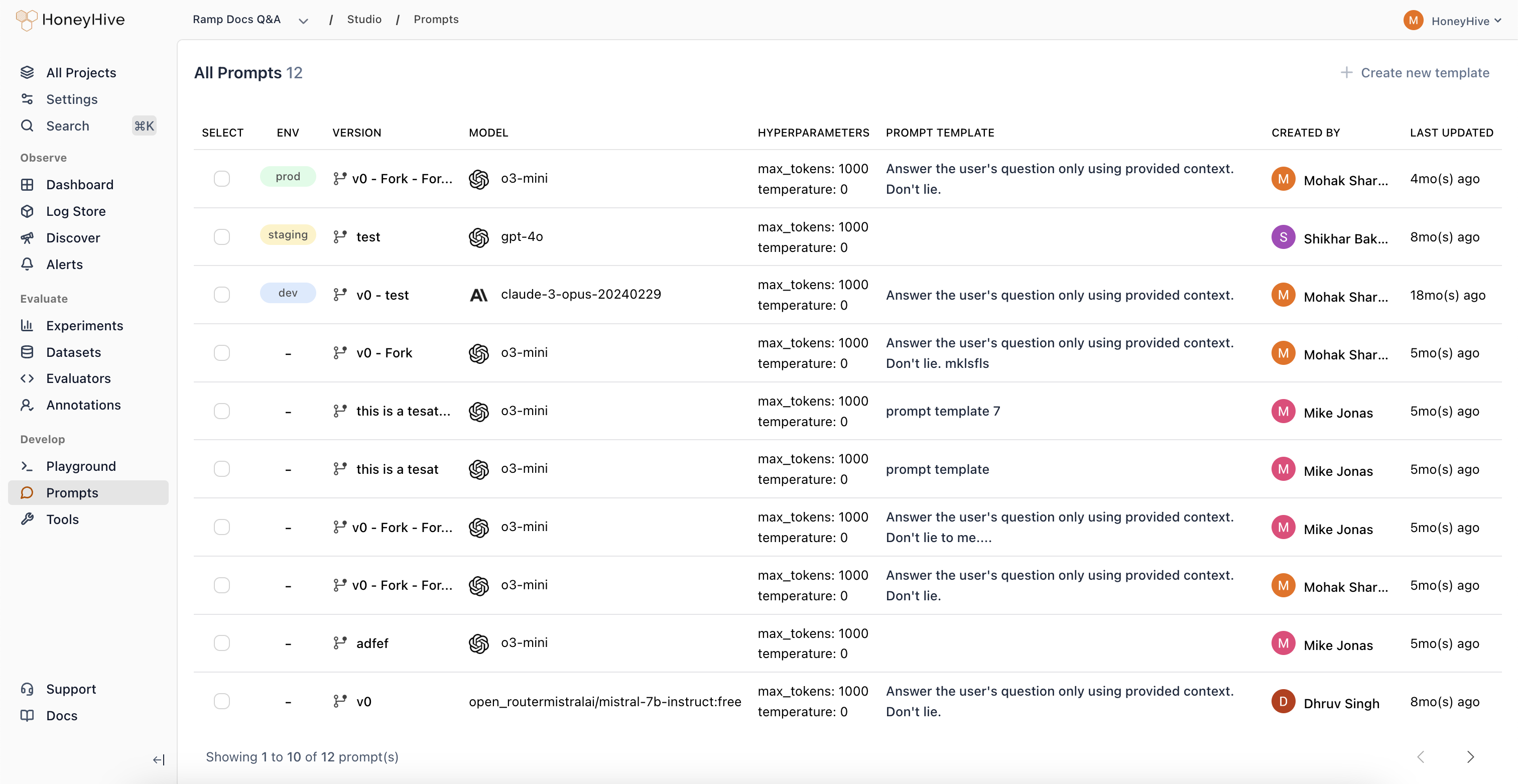
Prompt
A prompt is a versioned configuration for an LLM call. It includes the model name, provider, prompt template, and hyperparameters (temperature, tools, etc.).