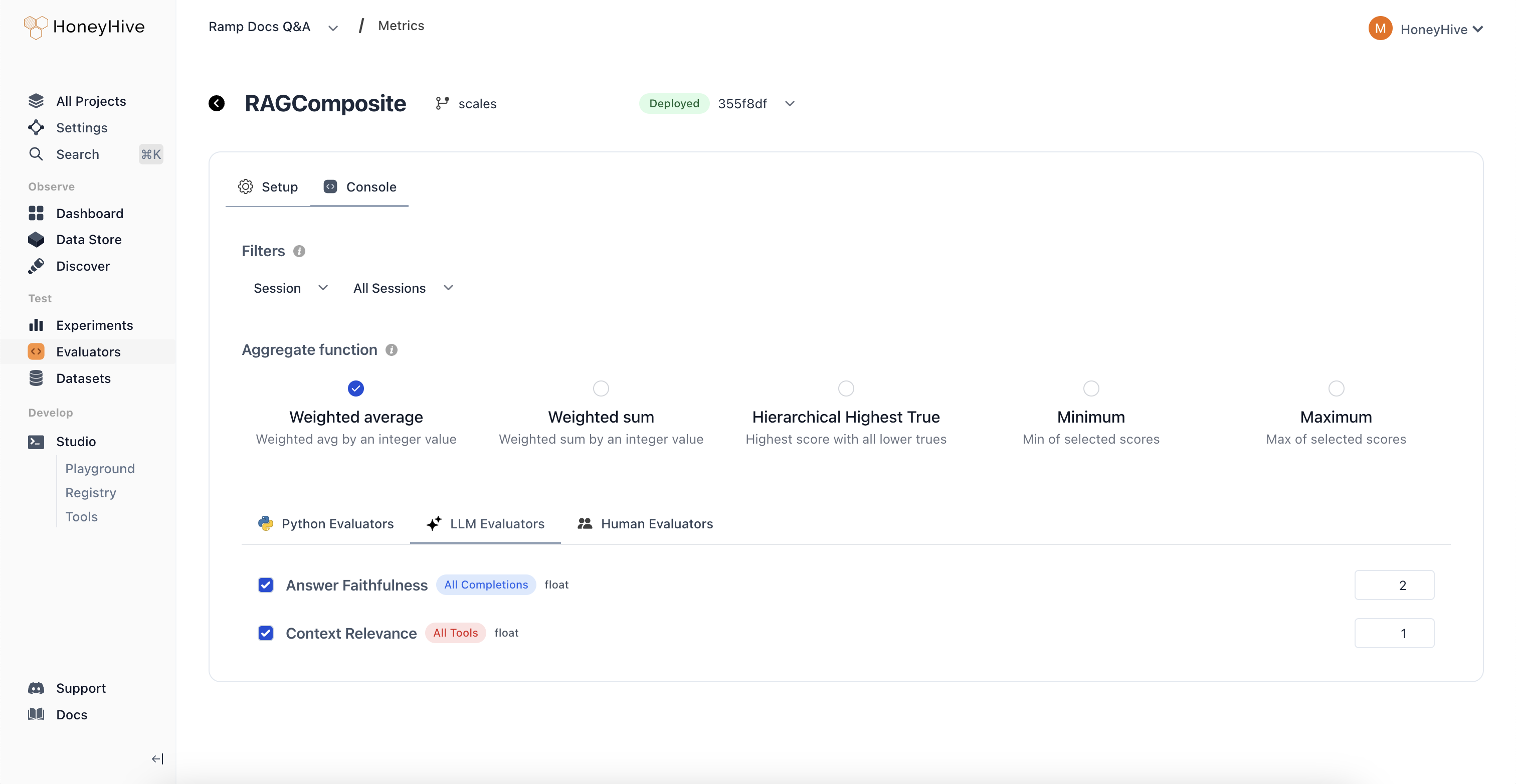
Creating a Composite Evaluator
- Navigate to the Metrics tab in the HoneyHive console.
- Select or create a new composite evaluator (e.g., “RAGComposite”).
Configuration
Event Filters
You can choose to compute your evaluator over a specificevent_type and event_name in your pipeline, including the root span (session).
Adding Evaluators
Add individual evaluators to your composite. Select from existing Python, LLM, or Human evaluators.Aggregate Functions
Select one of the following aggregation methods:Weighted average
Calculates the average of all component evaluator scores, taking into account their assigned weights. Formula:Σ(score * weight) / Σ(weights)
Example:
- Evaluator A (weight 2, score 4)
- Evaluator B (weight 1, score 3) Result: (4 * 2 + 3 * 1) / (2 + 1) = 3.67
Weighted sum
Sums the weighted scores of all component evaluators. Formula:Σ(score * weight)
Example:
- Evaluator A (weight 2, score 4)
- Evaluator B (weight 1, score 3) Result: (4 * 2) + (3 * 1) = 11
Hierarchical Highest True
This function is designed for boolean evaluators with associated priority levels. It determines the highest consecutive “true” score across evaluators, considering their priority order rather than their listed order. Process:- Evaluators are first sorted by their priority (lower number indicates higher priority).
- Starting from the highest priority, the function counts consecutive “true” results until it encounters a “false”.
- The priority number of the last consecutive “true” result is returned as the score.
- Evaluator A (Priority 1, result: True)
- Evaluator C (Priority 2, result: True)
- Evaluator B (Priority 3, result: False)
- Evaluator D (Priority 4, result: True)
Minimum
Returns the minimum score among all component evaluators, regardless of their weights. Example:- Evaluator A (score 4)
- Evaluator B (score 3)
- Evaluator C (score 5) Result: 3
Maximum
Returns the maximum score among all component evaluators, regardless of their weights. Example:- Evaluator A (score 4)
- Evaluator B (score 3)
- Evaluator C (score 5) Result: 5
Usage Notes
- There is no limit to the number of individual evaluators that can be included in a composite evaluator.
- Weights for each component evaluator are set manually by the user.
- Composite evaluators can combine results from different types of evaluators (Python, LLM, Human) in a single score.
Best Practices
- Choose an appropriate aggregation function based on your evaluation needs:
- Use Weighted average or Weighted sum for a balanced overall score.
- Use Hierarchical Highest True for sequential or dependent criteria.
- Use Minimum or Maximum to focus on worst-case or best-case performance respectively.
- Carefully consider the weights assigned to each component evaluator to reflect their relative importance.
- When using Hierarchical Highest True, assign priorities to your evaluators based on their criticality to the overall evaluation.
- Regularly review and adjust your composite evaluators to ensure they accurately represent your evaluation criteria as your project evolves.
- Use composite evaluators to get a holistic view of your system’s performance, but also monitor individual evaluator scores for detailed insights.