Creating an LLM Evaluator
- Navigate to the Evaluators tab in the HoneyHive console.
- Click
Add Evaluatorand selectLLM Evaluator.
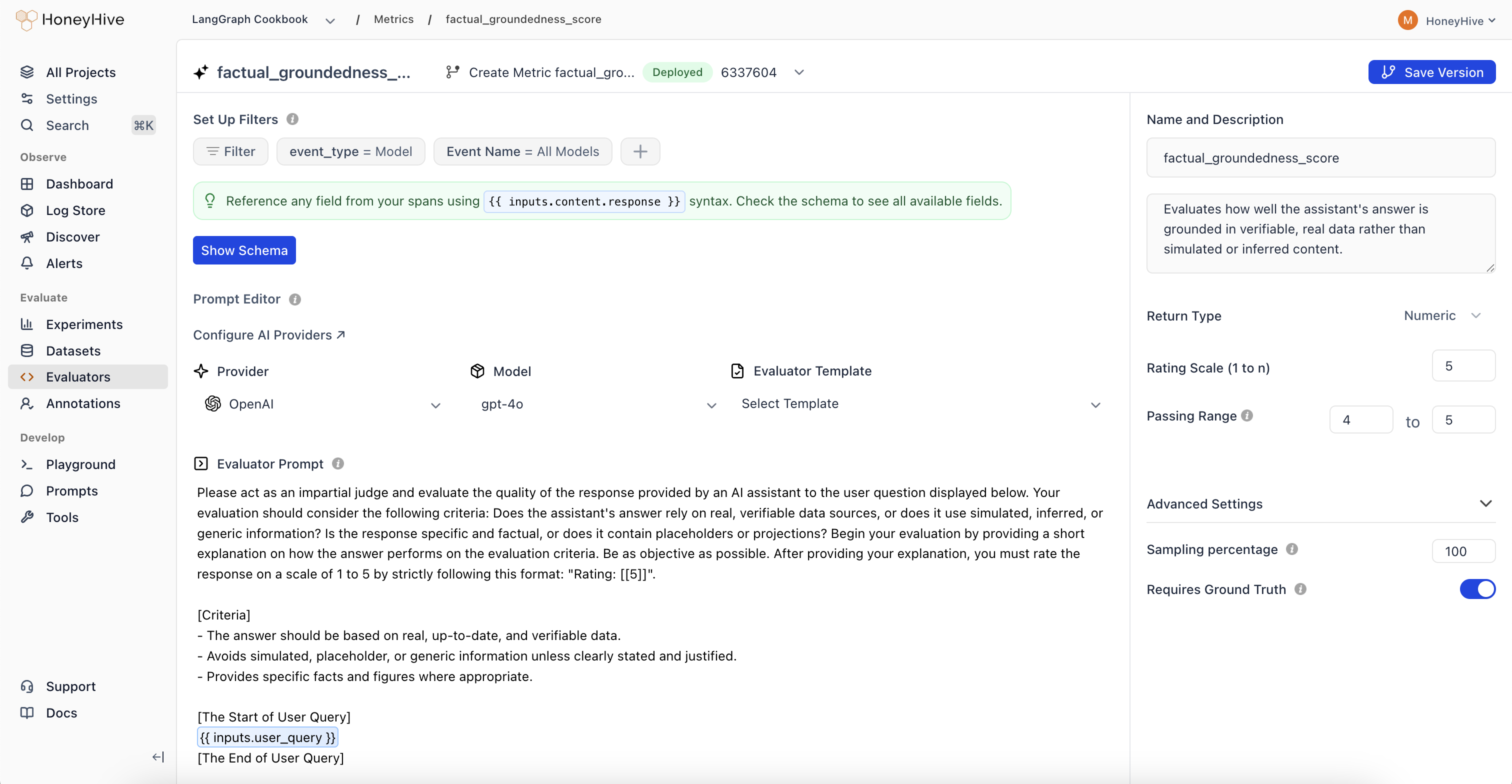
HoneyHive’s server-side LLM evaluators are powered by OpenAI’s
gpt-4o model. Event Schema
The base unit of data in HoneyHive is called anevent, which represents a span in a trace. A root event in a trace is of the type session, while all non-root events in a trace can be of 3 core types - model, tool and chain.
All events have a parent-child relationship, except
session event, which being a root event does not have any parents.session: A root event used to group together multiplemodel,tool, andchainevents into a single trace. This is achieved by having a commonsession_idacross all children.modelevents: Used to track the execution of any LLM requests.toolevents: Used to track execution of any deterministic functions like requests to vector DBs, requests to an external API, regex parsing, document reranking, and more.chainevents: Used to group together multiplemodelandtoolevents into composable units that can be evaluated and monitored independently. Typical examples of chains include retrieval pipelines, post-processing pipelines, and more.
Event Properties
Event Properties
For the purpose of setting evaluators, we’ll focus on the following event properties:
event_type: The type of event. Can bemodel,tool,chain, orsession.event_name: The name of the event or session. This can be used to identify a specific event or session you want to evaluate.inputs: The inputs to the event or session. This can be the prompt, chat history, dynamic insertion variables in your prompt template, query for your retrieval pipeline, etc.output: The output of the event or session. This can be a completion, a vector DB response, an API response, etc.feedback: A JSON object presenting user feedback for the event. This object also containsGround Truth.
Evaluation Prompt
Define your evaluation prompt:Looking for ready-made examples? Check out our list of LLM Evaluator Templates.
Configuration
Return Type
Boolean: For true/false evaluationsNumeric: For numeric scores or ratingsString: For categorical evals or other objects
Passing Range
Passing ranges are useful in order to be able to detect which test cases failed in your evaluation. This is particularly useful for defining pass/fail criteria on a datapoint level in your CI builds.Online Evaluation
Toggle to enable real-time evaluation in production. We define production as any traces wheresource != evaluation when initializing the tracer.
Enable sampling
Sampling allows us to run our evaluator over a smaller percentage of events from production. This helps minimize costs while still providing valuable insights about the performance of our application. When deploying evaluators in production or staging environments, be sure to select an appropriate sampling rate based on your estimated event ingestion rate to maintain optimal performance and cost efficiency. We’ll choose to set sampling percentage to 25% in this example.Sampling only applies to events where
source is not evaluation or playground, i.e. typically only production or staging environments. You can not sample events when running offline evaluations.Event Filters
You can choose to compute your evaluator over a specific event type and event name, or over all sessions or a particular session name if you’re looking to evaluate properties that are spread across an entire trace.
Validating the evaluator
LLM evaluators can often be unreliable and need validation and alignment with your own judgement before you can deploy them. You can quickly test your evaluator with the built-in IDE by either defining your datapoint to test against in the JSON editor, or retrieving 5 most recent events from your project to test your evaluator against.
Create in the top right corner.