Creating a Python Evaluator
- Navigate to the Evaluators tab in the HoneyHive console.
- Click
Add Evaluatorand selectPython Evaluator.
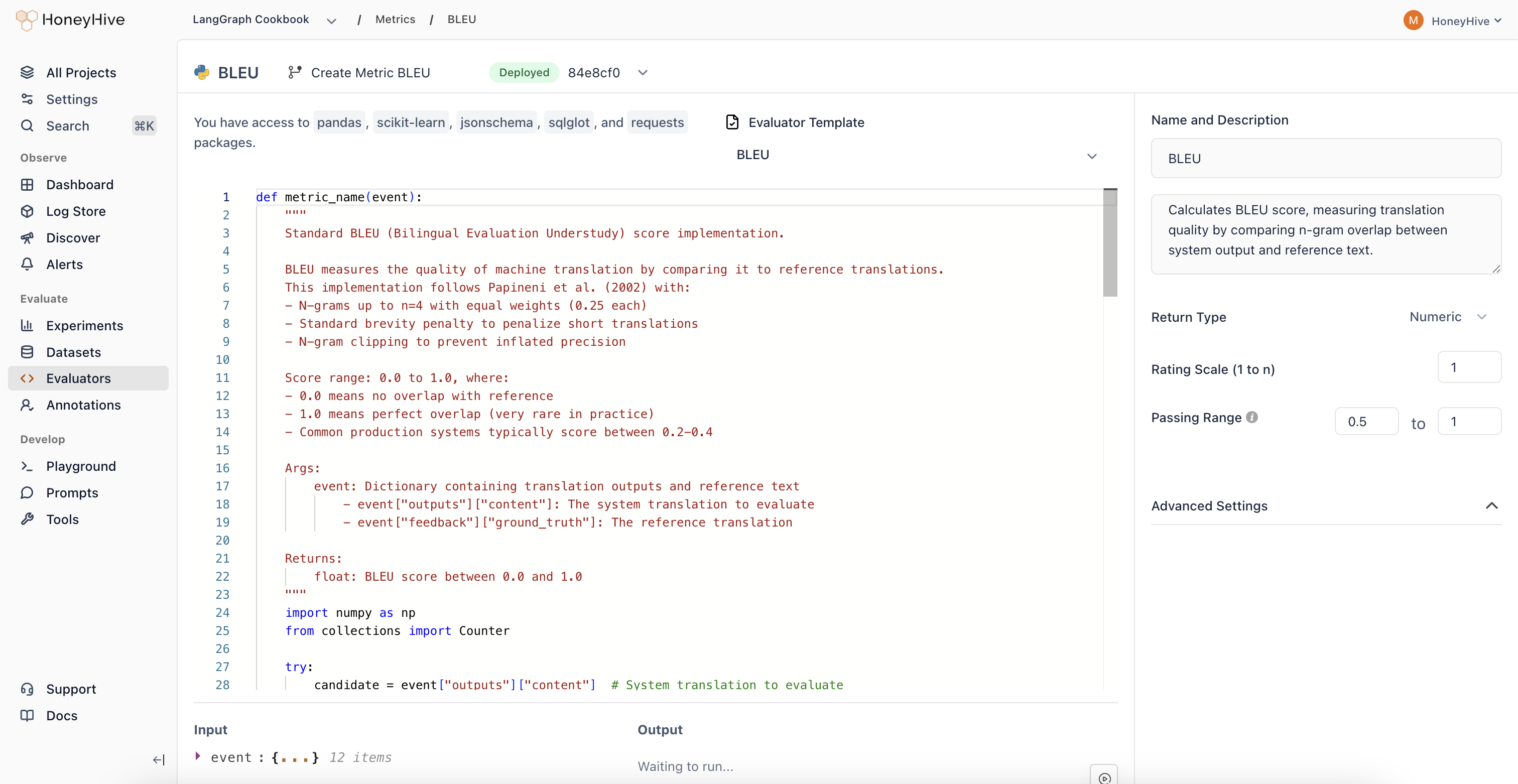
HoneyHive’s server-side Python evaluators have access to Python’s complete standard library and popular third-party packages including
pandas, scikit-learn, jsonschema, sqlglot, and requestsEvent Schema
Python evaluators operate onevent objects. Key properties include:
event_type: Type of event (e.g., “model”, “tool”, “chain”, “session”)event_name: Name of the specific eventinputs: Input data for the eventoutputs: Output data from the eventfeedback: User feedback and ground truth data
Full Event Properties
Full Event Properties
event_type: The type of event. Can bemodel,tool,chain, orsession.event_name: The name of the event or session.inputs: The inputs to the event or session.output: The output of the event or session.feedback: A JSON object presenting user feedback for the event.
Evaluator Function
Define your evaluation logic in a Python function:Looking for ready-made examples? Check out our list of Python Evaluator Templates.
Configuration
Return Type
Boolean: For true/false evaluationsNumeric: For numeric scores or ratingsString: For categorical evals or other objects
Passing Range
Passing ranges are useful in order to be able to detect which test cases failed in your evaluation. This is particularly useful for defining pass/fail criteria on a datapoint level in your CI builds.Online Evaluation
Toggle to enable real-time evaluation in production. We define production as any traces wheresource != evaluation when initializing the tracer.
Event Filters
You can choose to compute your evaluator over a specificevent_type and event_name in your pipeline, including the root span (session).
Testing
You can quickly test your evaluator with the built-in IDE by either defining your datapoint to test against in the JSON editor, or retrieving any recent events from your project to test your evaluator against.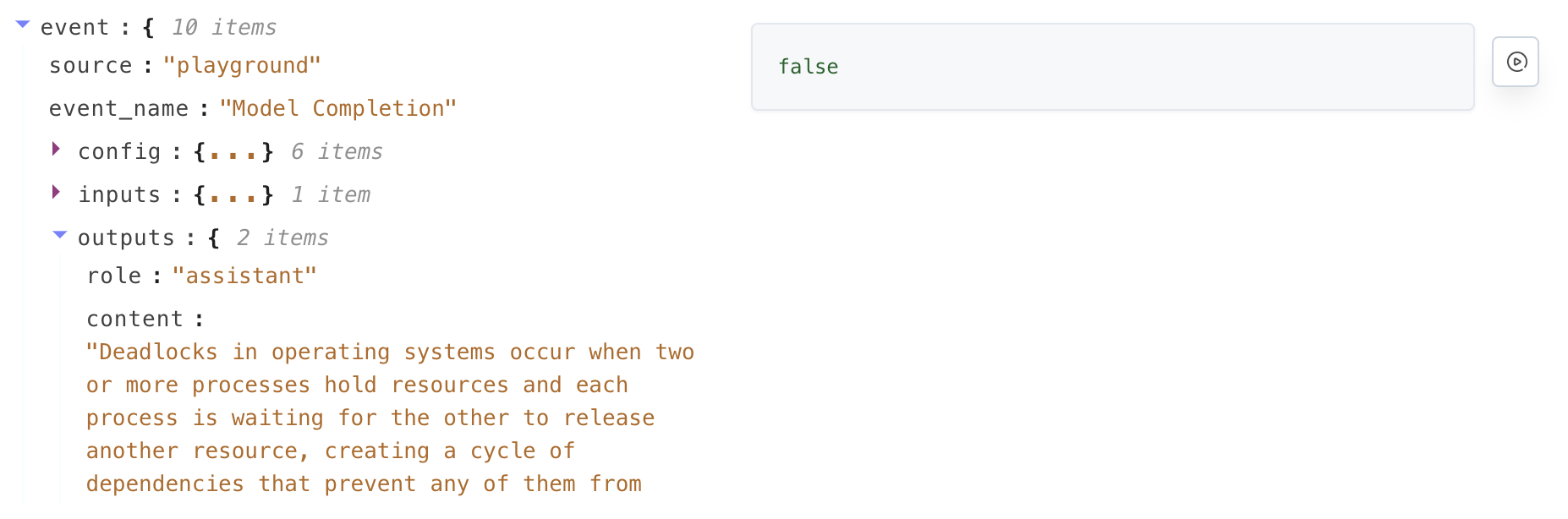
Commit in the top right corner.