Looking for the latest HoneyHive docs? See HoneyHive v2.
Key characteristics of HoneyHive evaluators
HoneyHive provides a flexible and comprehensive evaluation framework that can be adapted to various needs and scenarios:Development Stages
- Offline Evaluation: Used during development and testing phases, including CI/CD pipelines and debugging sessions, where immediate results aren’t critical. In this stage, you can build test suites comprised of carefully curated examples of scenarios you wish to test, with or without ground truths.
- Online Evaluation: Applied to production systems for real-time monitoring and quality assessment of live applications, enabling real-time quality monitoring, continuous validation of model outputs, and production guardrails and safety checks.
For an example of an offline evaluation with client-side evaluators, see how to run an experiment here.
Implementation Methods
Evaluators can be implemented using three primary methods:- Python Code Evaluators: Custom functions that programmatically assess outputs based on specific criteria, such as format validation, content checks, or metric calculations.
- LLM-Assisted Evaluators: Leverage language models to perform qualitative assessments, such as checking for coherence, relevance, or alignment with requirements.
- Domain Expert (Human) Evaluators: Enable subject matter experts to provide direct feedback and assessments through the HoneyHive platform.
Execution Environment
Evaluators can be run either locally (client-side) or remotely (server-side), each with its own set of advantages and use cases.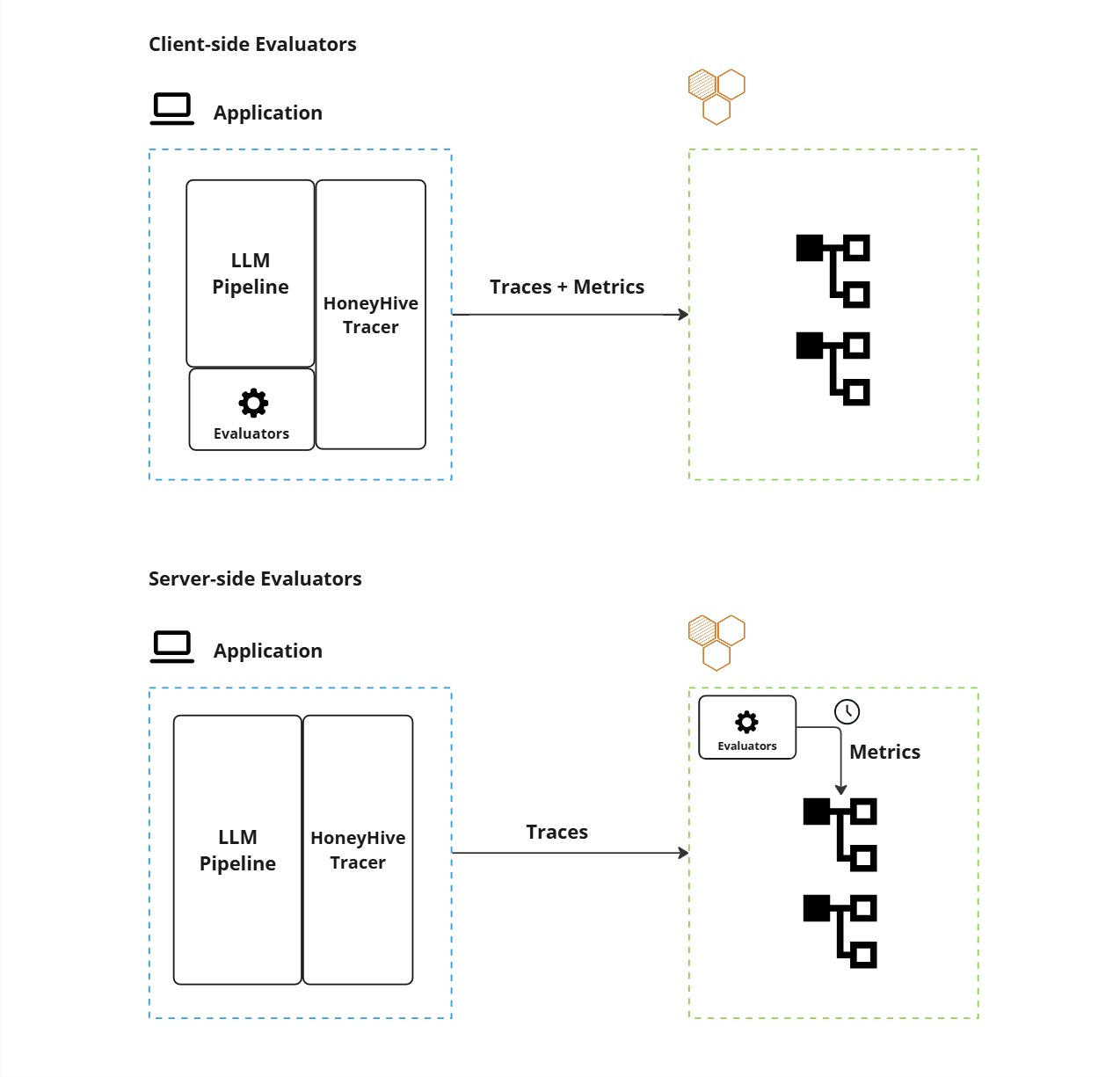
Comparison of Client-side and Server-side Evaluators
- Client-Side Execution: Evaluators run locally within your application environment, providing immediate feedback and integration with your existing infrastructure.
- Pros:
- Quick validations and guardrails
- Offline experiments and CI/CD pipelines
- Real-time format checks and PII detection
- Cons:
- Limited by local resources and lack centralized management.
- Pros:
Client-side evaluators can be useful in different scenarios. Here are some examples that illustrate their use:
- Refer to Client-side Evaluators to see how to use client-side evaluators for both tracing and experiments scenarios.
- Check out our tutorial on Evaluating Advanced Reasoning Models on Putnam 2023 for an example of setting up an evaluation run using a client-side LLM-as-a-Judge evaluator.
- Server-Side Execution: Evaluators operate remotely on HoneyHive’s infrastructure.
- Pros:
- Asynchronous processing for resource-intensive tasks
- Centralized management and versioning
- Better scalability for large datasets
- Support for human evaluations and post-ingestion analysis
- Cons:
- Higher latency since results aren’t immediately available.
- Pros:
If you want to know more about how to set up server-side Python, LLM, or Human-based evaluators, please refer to the Python evaluator, LLM Evaluator, Human Annotation pages.
Evaluation Scope
HoneyHive provides flexible granularity in evaluation, allowing you to:- Assess entire end-to-end pipelines
- Evaluate individual steps within your application flow
- Monitor specific components such as model calls, tool usage, or chain execution
- Track and evaluate sessions that group multiple operations together
enrich_step:
If you want to know more about how to log client-side evaluations on specific traces and spans, explore our tracing documentation.