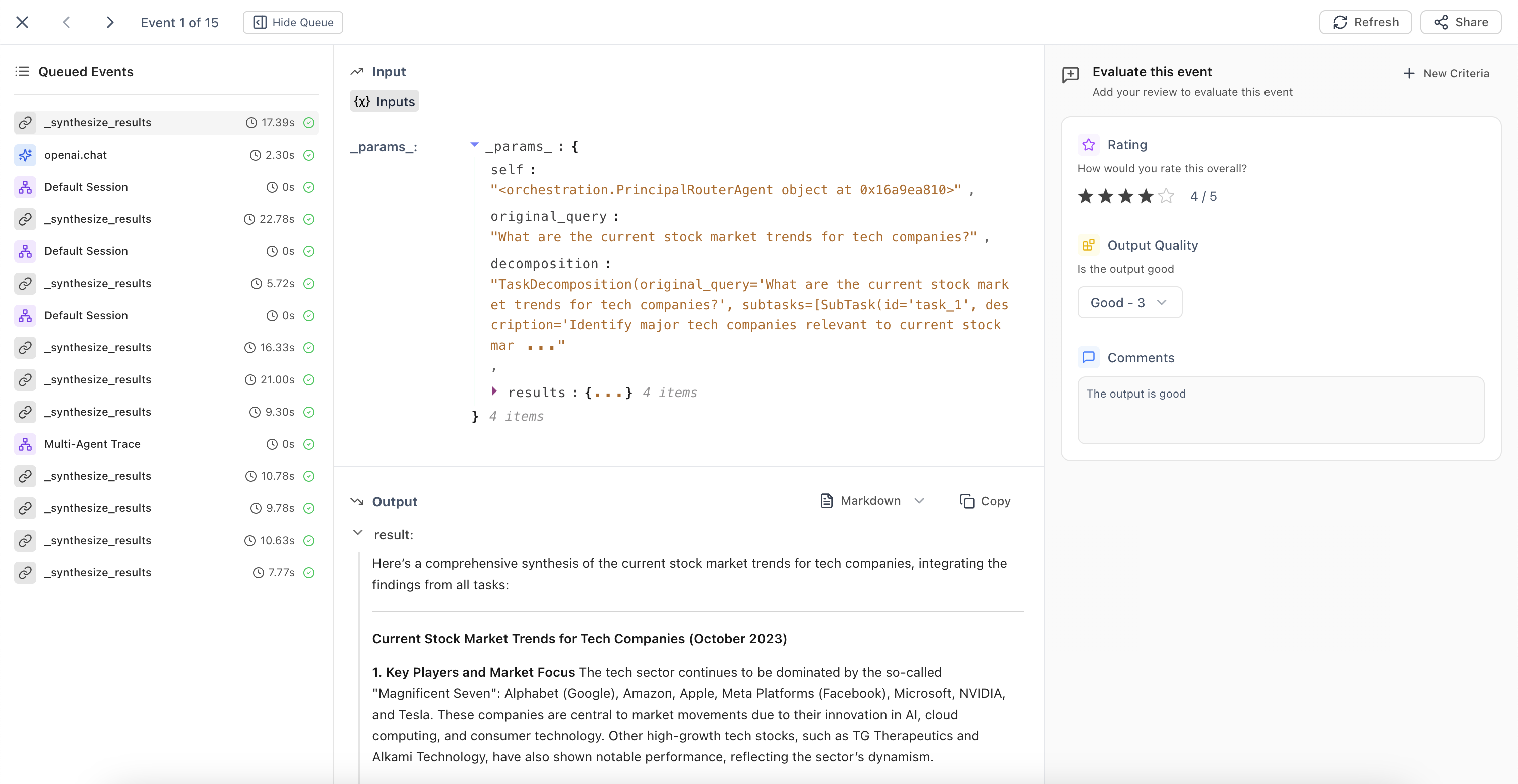
Creating a Human Evaluator
- Navigate to the Evaluators tab in the HoneyHive console.
- Click
Add Evaluatorand selectHuman Evaluator.
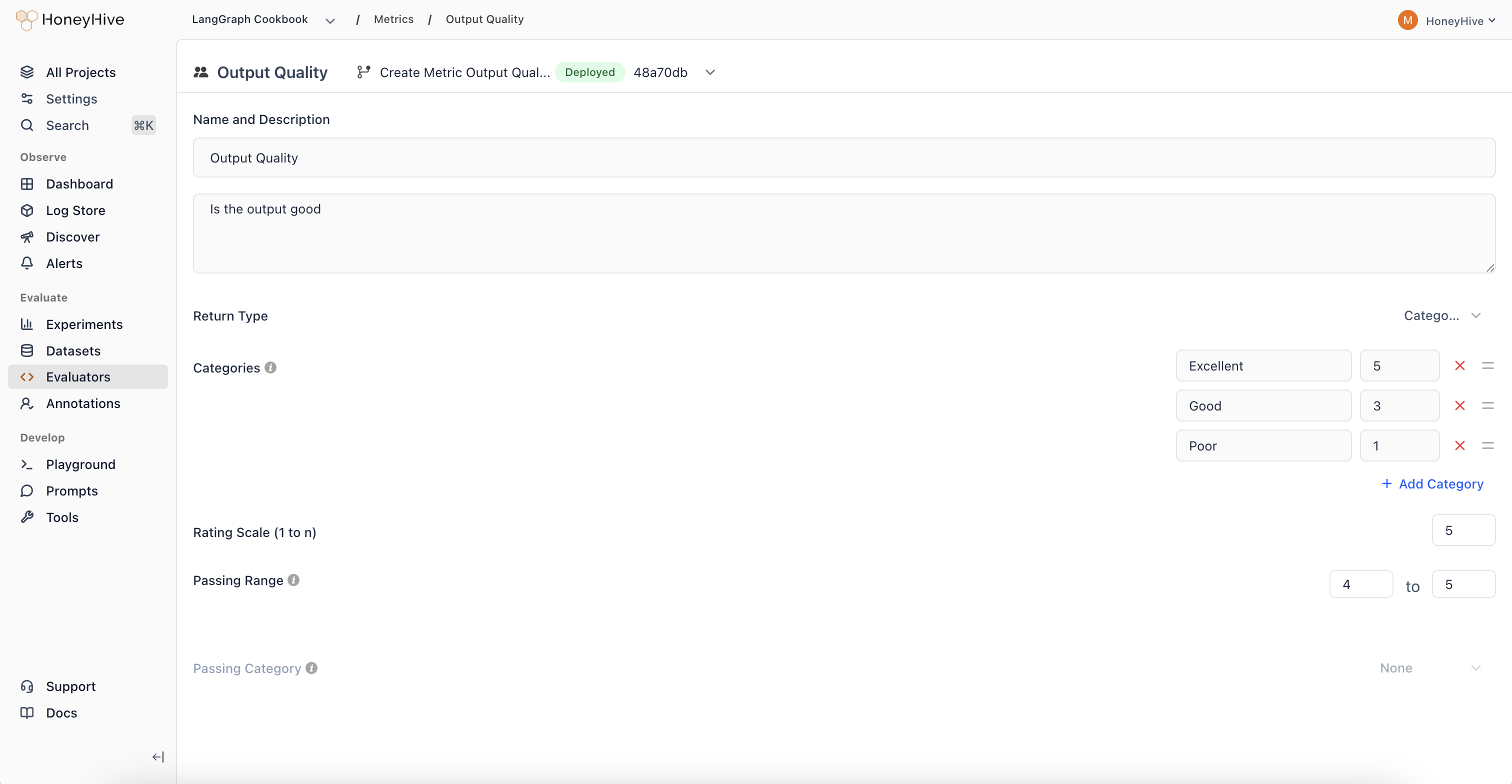
Evaluation Criteria
Define clear evaluation criteria for annotators in theDescription field:
Configuration
Return Type
Options:Numeric: For ratings on a scaleBinary: For yes/no evaluationsNotes: For free-form text feedbackCategorical: For categorization tasks
Rating Scale
Fornumeric return type and, in some cases, categorical return type (i.e where numerical labels are defined), specify the scale (e.g., 1-5).
Passing Range
Define the range of scores considered acceptable.In-App Annotation
Once created, human evaluators are available throughout the UI - in traces,Review Mode or Annotation Queues. You can invite domain experts to annotate traces in any project.