Configure HoneyHive online evaluations to score production traces automatically with code or LLM judges and surface quality drift on your dashboard.
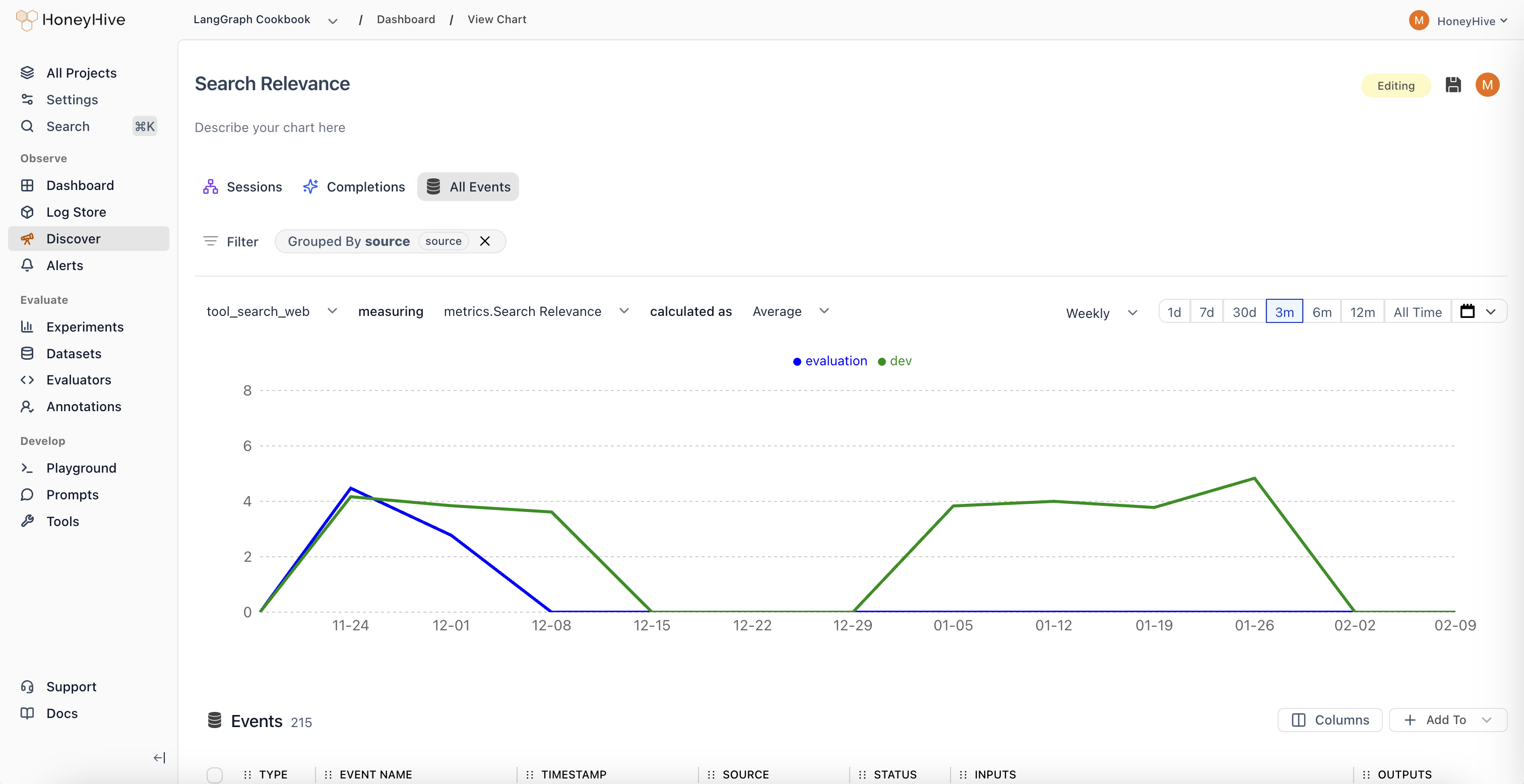
Online evaluations run your evaluators automatically on ingested traces. This gives you continuous quality scores alongside your cost and latency metrics, without adding latency to your application.
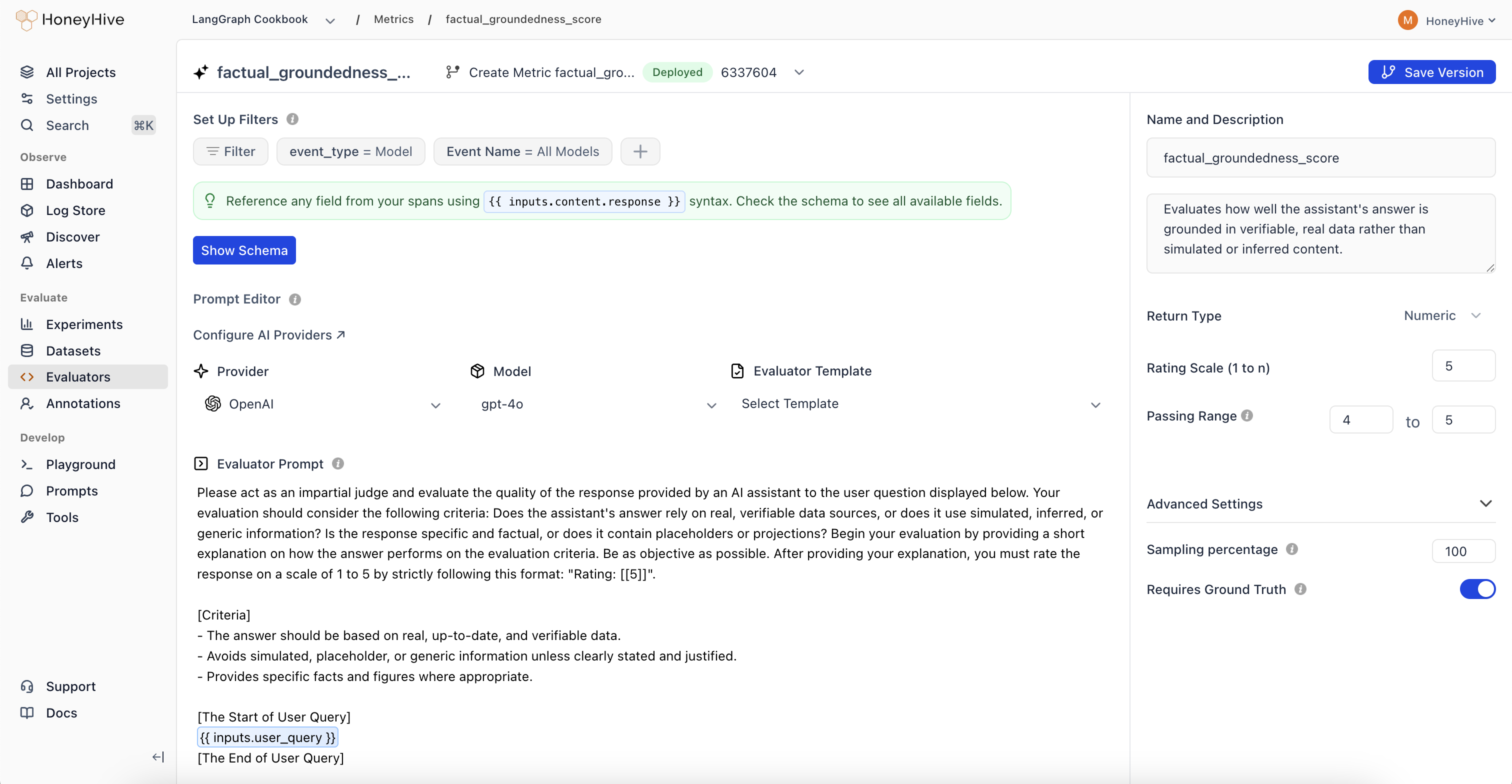
LLM evaluator configuration with event filters, sampling percentage, and prompt editor
3
Enable the evaluator
Toggle the Enabled switch in the evaluators table. This tells HoneyHive to run this evaluator on all matching traces.
4
Set a sampling percentage
Set the Sampling percentage to control what fraction of matching events get evaluated (e.g., 25%). This controls cost for LLM-based evaluators at high volumes.
Each evaluator has event filters that determine which traces it runs on. You can filter by event type, event name, and any event property from your schema. For example, you might run a hallucination evaluator only on model events named generate_response, or add a filter like metadata.environment is production to limit evaluation to specific contexts.See Event Filters for the full list of supported filter options and operators (which vary by field type).
Use client-side evaluators for checks that need to happen during execution (guardrails, blocking unsafe responses). Use online evaluations for quality scoring that can happen asynchronously.
Check event filters: Verify the evaluator’s event type and event name filters match your traces. Filters are AND-ed, so all conditions must match.
Check enabled status: The evaluator must be toggled Enabled in the evaluators table.
Check sampling: At low sampling percentages, some matching events are intentionally skipped. Increase sampling to verify the evaluator works, then reduce.
Check event properties: Property-based filters use dot-path matching (e.g. metadata.environment). Verify the property exists on your events and the value matches.
If an evaluator fails 100+ times within 1 hour, HoneyHive automatically disables it and creates a version snapshot. This prevents a broken evaluator from consuming resources across all your traces.To recover:
Go to the Evaluators table and find the disabled evaluator
Check the error by running the evaluator manually against a sample event