dataset_id) and compare their results side-by-side. The dataset is the input data for the experiment which can be through HoneyHive Datsets or inputs passed. This is particularly useful when you want to benchmark different models, prompts, or configurations against each other.
- step level comparisons
- view metric aggregates
- find improved/regressed events
- compare outputs
- analyze metric distribution
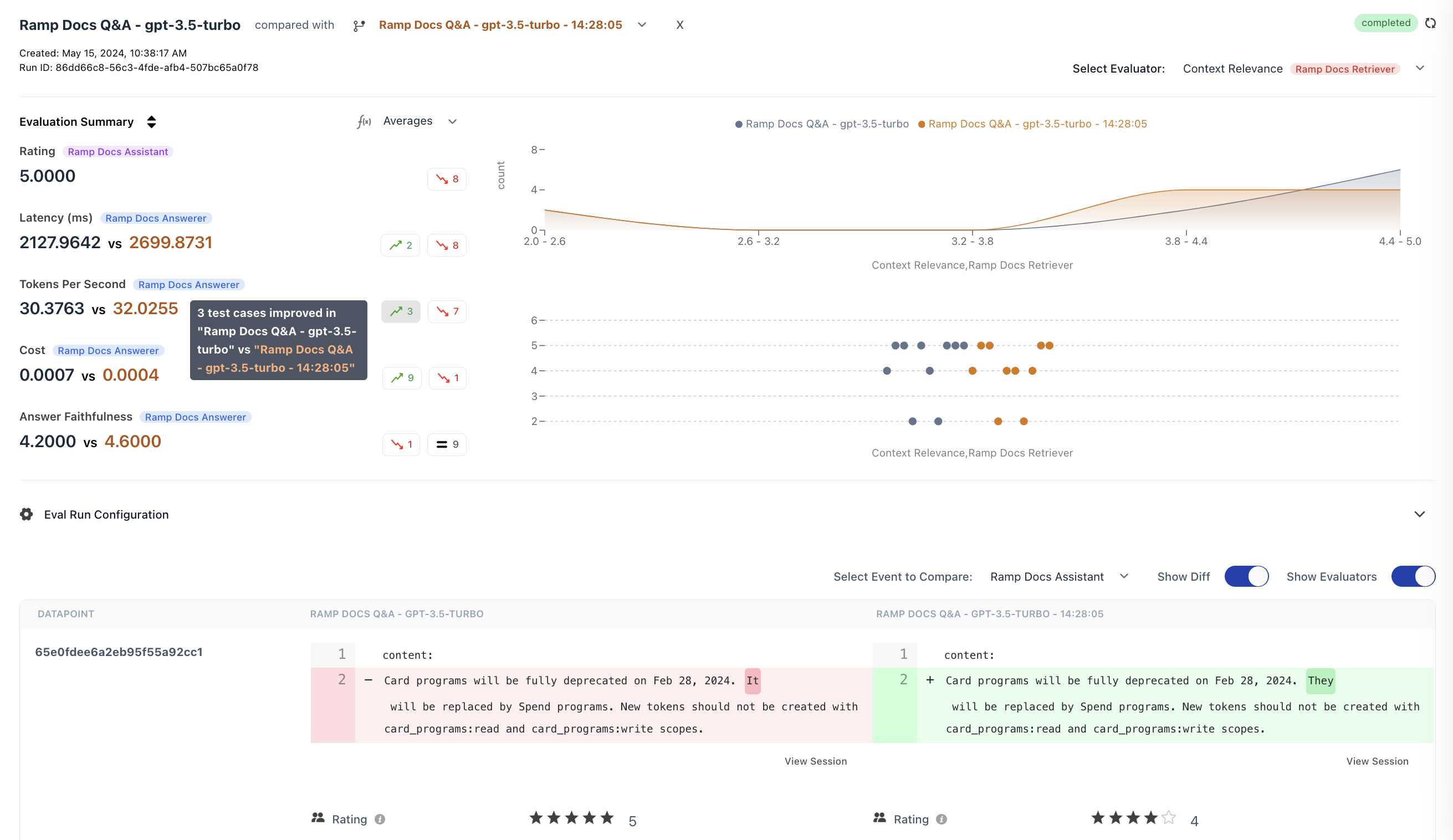
Navigating the Comparison View
Let’s walk through the key features of the comparison view to help you effectively compare your experiments.Advanced Comparison Features
1. Step Level Comparisons
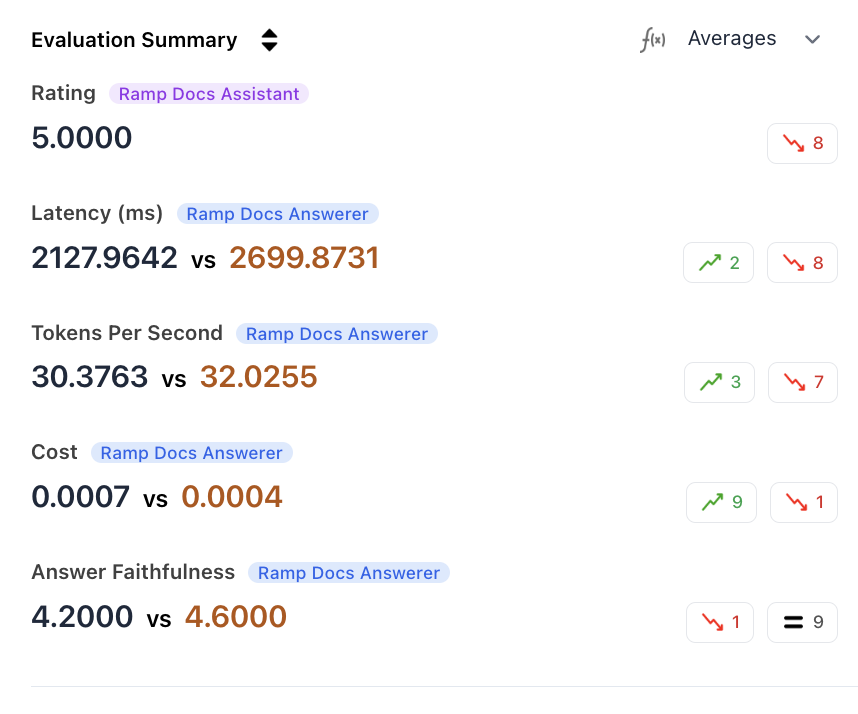
HoneyHive allows you to compare experiments at each individual step level, giving you granular insights into how different configurations perform at specific stages of your workflow.2. Aggregated Metrics
HoneyHive automatically calculates and compares aggregates from:- Server-side metrics
- Client-side metrics
- Composite metrics at the session level
3. Improved/regressed events
Filter for events that have improved or regressed in specific metrics. Select the metric and operation you want.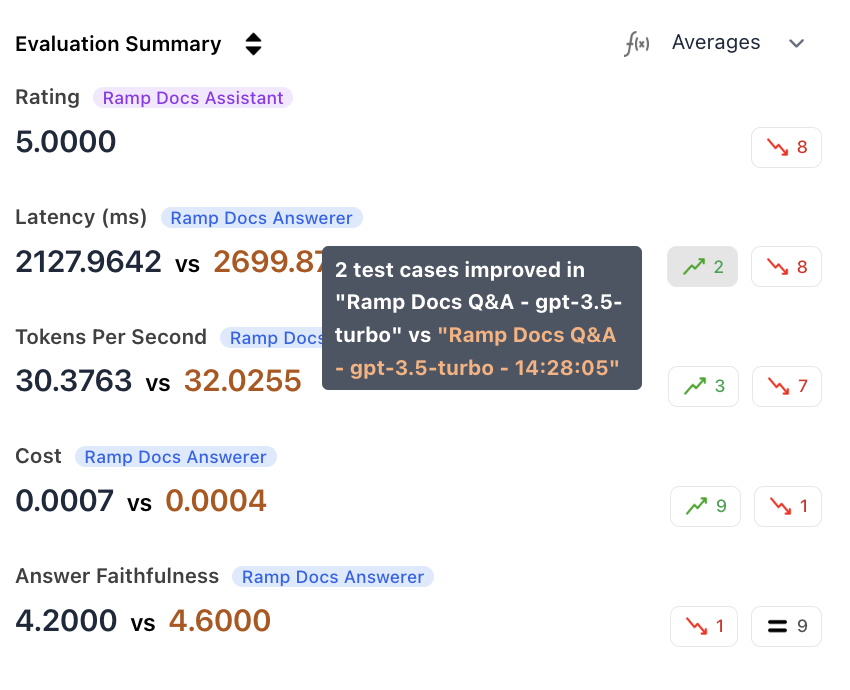
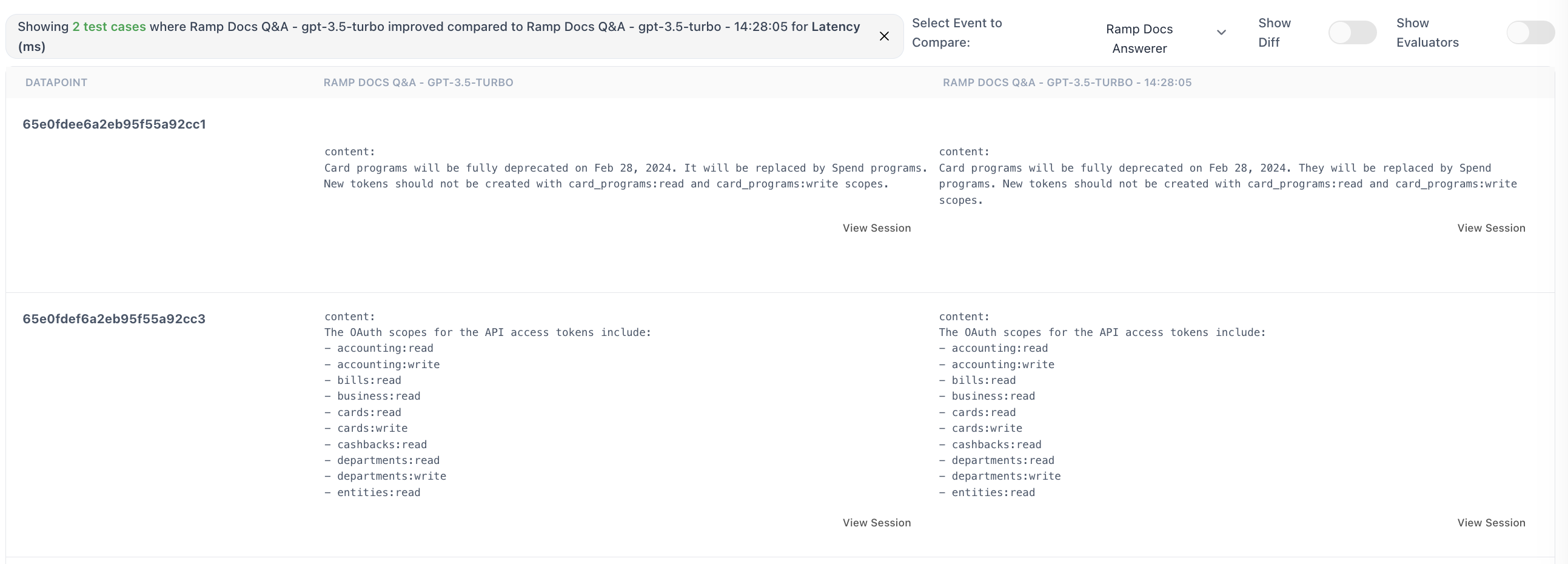
4. Output Diff Viewer
Compare outputs and metrics of corresponding events with the same event name.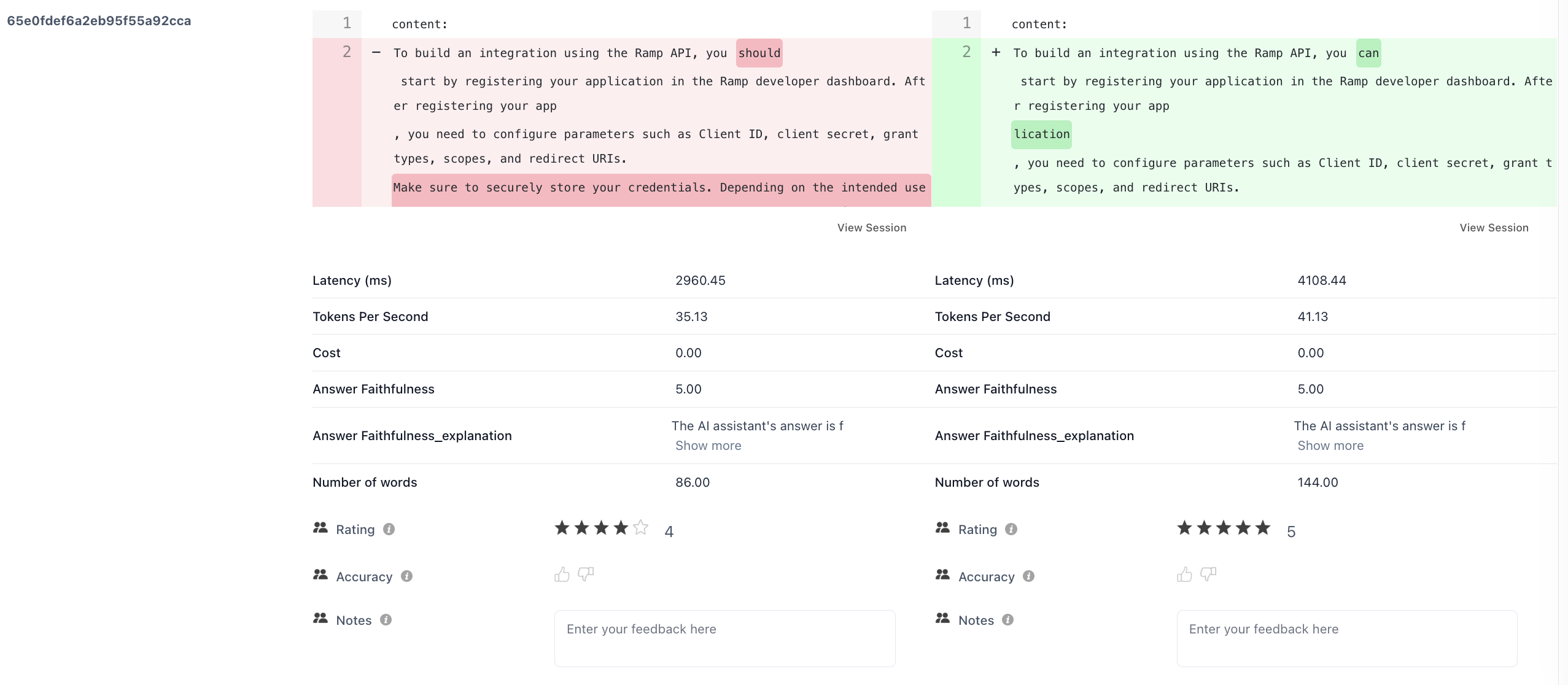
5. Metric Distribution
Analyze the distribution of various metrics for deeper insights.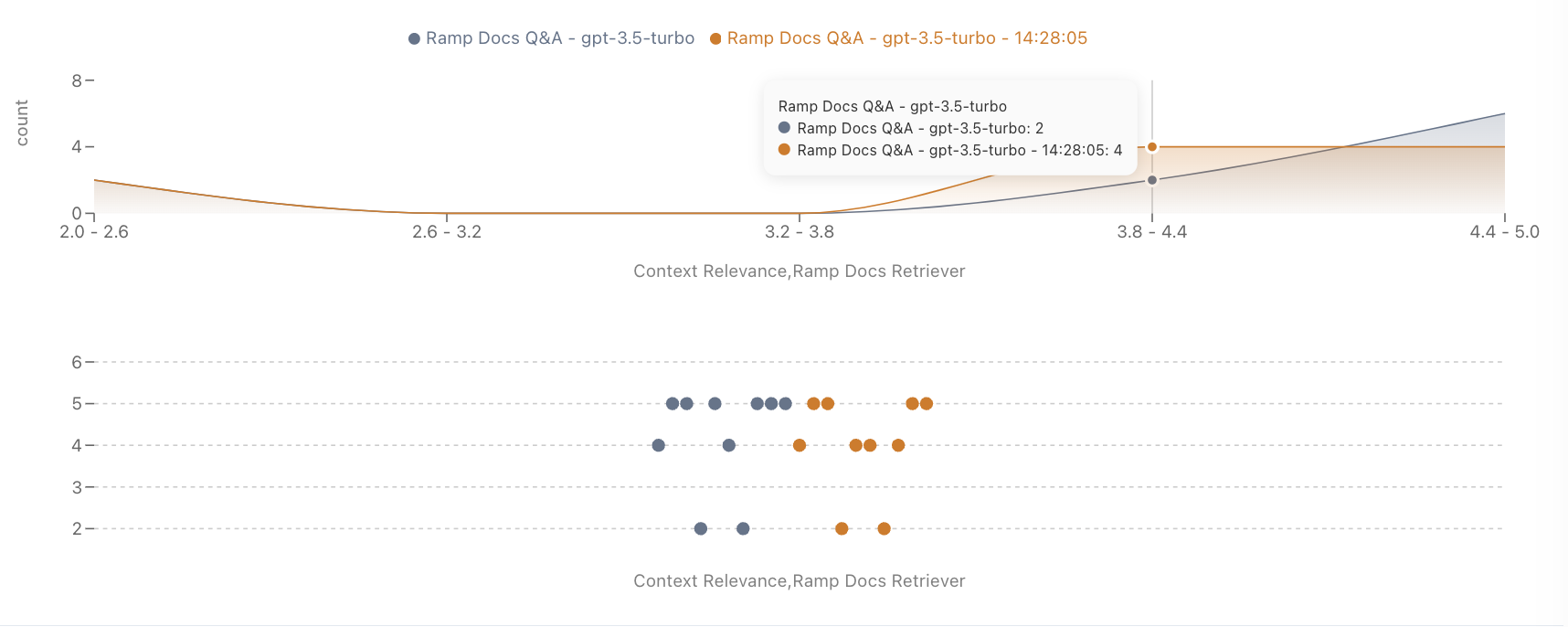
Best Practices
- Use a consistent dataset for all compared experiments.
- Isolate one change at a time (e.g., model, prompt, temperature) to understand its specific impact.
- Ensure a sufficient sample size for statistically significant conclusions.
- Document configurations used in each experiment for future reference.