- Evaluate the quality of historical interactions.
- Benchmark different versions of prompts or models using past data.
- Apply new evaluation metrics to existing logs without rerunning the original generation process.
This guide assumes you are familiar with how experiments function in HoneyHive. If you need a refresher, please visit the Experiment’s Introduction page.
Overview
For this example, we will use a set of examples from the CNN / DailyMail dataset, to simulate a summarization task. The dataset contains two key components:article: Contains the full text of news articles, which serves as our inputhighlights: Contains human-written bullet-point summaries of each article, which we’ll use to simulate the expected output from our LLM summarization task
Step-by-Step Implementation
- Python
- TypeScript
Full code example
Here’s a minimal example assuming you’ve loaded your external data into a list format:Sample eval script for external logs
Sample eval script for external logs
scikit-learn library for keyword extraction. Install it using pip install scikit-learn.Creating the Dataset
To evaluate your model’s performance, you’ll need to transform your external log data into a structured format that the evaluation framework can process. The framework expects a Python list of dictionaries, where each dictionary represents a single interaction containing:- Request inputs
- Generated outputs
- Ground truth information (if available)
evaluate function with your dataset and defined evaluators.For the purposes of our example, we’ll assume our data has already been transformed into this required format:Python
This guide demonstrates defining the dataset directly within the script. Alternatively, you can upload your dataset (in JSON, JSONL, or CSV format) to the HoneyHive platform and then pass its
dataset_id when running the experiment.
For instructions on uploading and managing datasets within HoneyHive, please refer to the Upload Dataset page.Defining the Evaluators
To assess the quality of our summarizations, we’ll implement two key evaluators: compression ratio and keyword overlap. These metrics help us understand both the length efficiency and content preservation of our summaries.Compression ratio
The compression ratio evaluator measures how concise our summary is compared to the original article:Python
Keyword overlap
The keyword overlap evaluator assesses how well our summary preserves the main topics and key information from the original text:Python
The evaluated function
The evaluated function is traditionally the function that will generate an output based on the input, like an LLM, whose outputs we want to evalute. In this case, we alreavy have our outputs in our logs, so we can define a simple pass-through function to use thehighglights column as our output:Python
Running the Experiment
Finally, we can run the experiment by passing our dataset, function and evaluators to the evaluation harness:Python
Dashboard View
Once the script runs, HoneyHive ingests each log entry as a trace, along with the computed client-side evaluator metrics. Navigate to your project in the HoneyHive dashboard to view the results. You can analyze distributions, filter by metadata, and compare metrics across your dataset.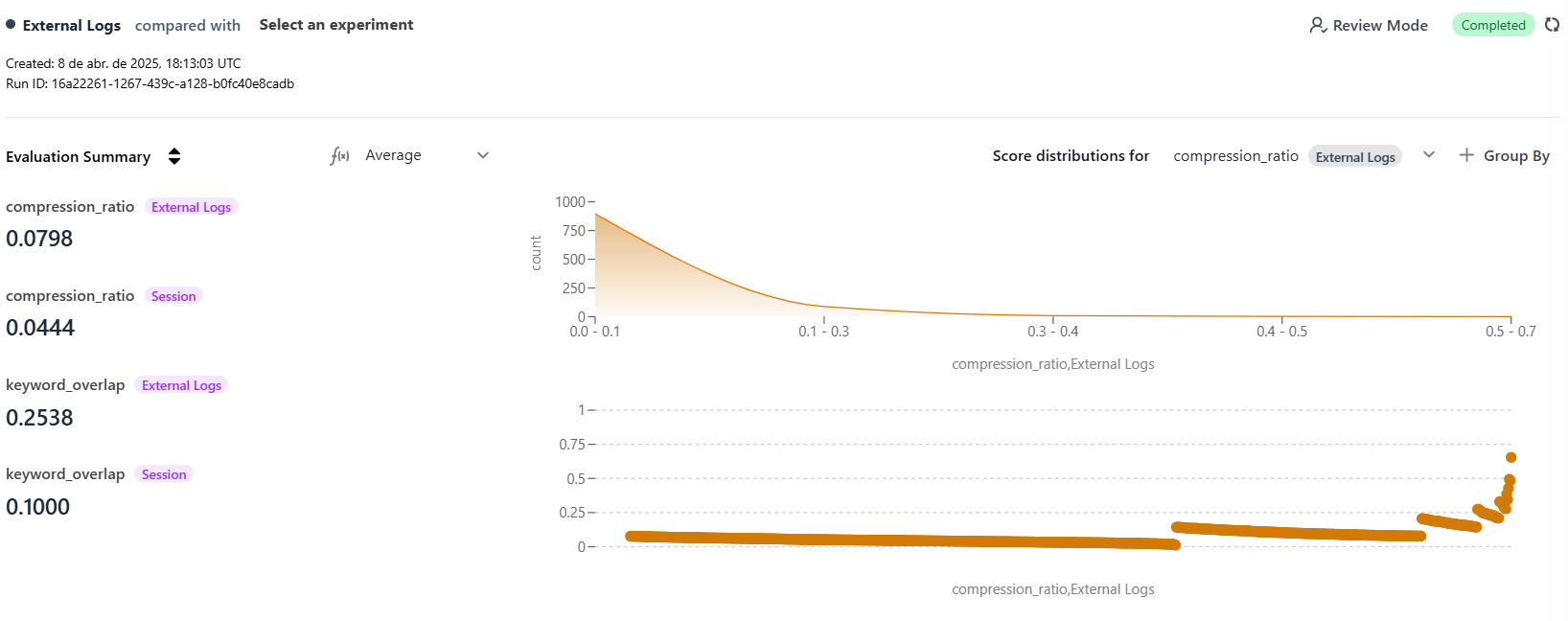
Conclusion
By mapping your existing external logs to the HoneyHiveevaluate function’s expected format, you can apply powerful client-side and server-side evaluations without rerunning the original AI/LLM calls. This provides a flexible way to assess performance, track quality over time, and gain insights from historical data.
Next Steps
Introduction to Evaluators
Deep dive into HoneyHive’s evaluation framework, including custom evaluators.
Server-Side Evaluators
Learn about configuring evaluators that run asynchronously on HoneyHive’s infrastructure.
Managing Datasets
Explore how HoneyHive helps manage datasets for evaluations and experiments.