- Python
- TypeScript
Full code
Below is a minimal example demonstrating how to run an experiment using managed datasets. This assumes you have already created a project and an API key. You will also need to provide a Dataset ID, which will be detailed in the following section.Sample script for running experiments when managing datasets in HoneyHive Cloud
Sample script for running experiments when managing datasets in HoneyHive Cloud
1
Create your dataset in jsonl format
Let’s first create our dataset in jsonl format. Simply create a file named
market_dataset.jsonl and paste the following content: In addition to JSONL, you can also create JSON or CSV files, as documented here.
2
Upload your dataset to HoneyHive
Now that we have our dataset in the proper format, let’s upload it to HoneyHive. HoneyHive supports 2 ways to upload it: via UI or via SDK.
In this guide, let’s do that through the UI:Be sure to save your Dataset ID - we will use it in the last step of this tutorial.
If you want to know more about uploading datasets to HoneyHive, check our Datasets Documentation Page.
3
Create the flow you want to evaluate
The remaining steps are the same as those seen on Experiments Quickstart.
Define the function you want to evaluate:The and The value returned by the function would map to the
inputs and ground_truths fields as defined in your dataset will be passed to this function.
For example, in one execution of this function, inputs might contain a dictionary like:ground_truths might contain a dictionary like:outputs field of each run in the experiment and will be accessible to your evaluator function, as we will see below.4
(Optional) Setup Evaluators
Define client-side evaluators in your code that run immediately after each experiment iteration. These evaluators have direct access to inputs, outputs, and ground truths, and run synchronously with your experiment.In addition to
inputs and ground_truths, the evaluator function has access to the return value from function_to_evaluate, which is mapped to outputs. In this example, outputs would contain a string with the model response, such as:For more complex multi-step pipelines, you can compute and log client-side evaluators on specific traces and spans directly in your experiment harness.
5
Run experiment
Finally, you can run your experiment with
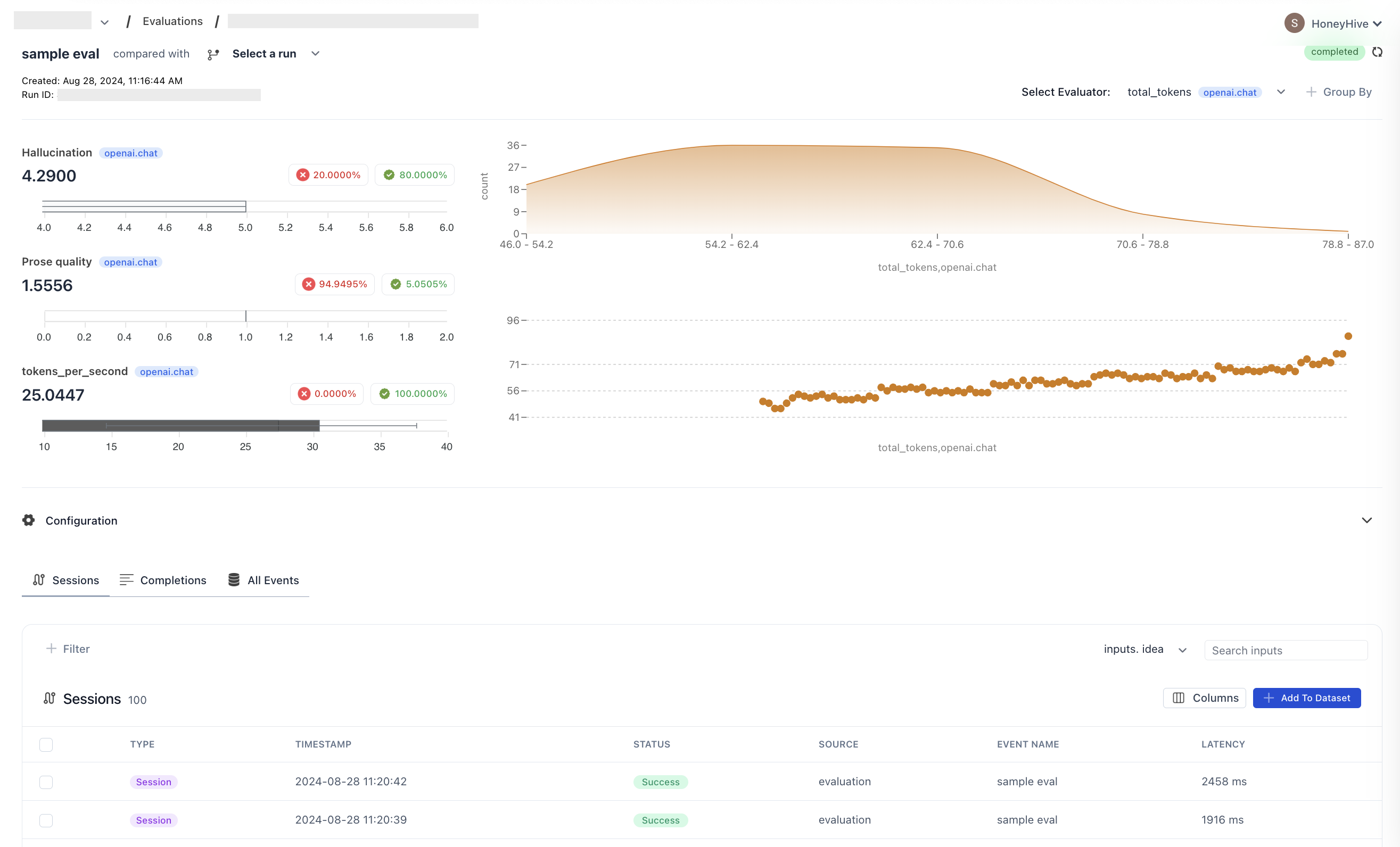
evaluate:Dashboard View
Remember to review the results in your HoneyHive dashboard to gain insights into your model’s performance across different inputs. The dashboard provides a comprehensive view of the experiment results and performance across multiple runs.